Содержание
Степень сжатия и октановое число бензина ✔ Таблица бензина
Октановое число — что это такое
Октановое число — это способность топлива противостоять детонации называется октановым числом. Чем оно выше, тем выше эта самая стойкость. Поэтому бензины с низким числом применяются в двигателях с низкой степенью сжатия, а с высоким октановым числом в двигателях с высокой степенью сжатия.
Часто возникает вопрос: бензин с каким октановым числом (ОЧ) можно заливать в двигатель, учитывая наше качество бензина.
Все просто. Открываем лючок заправочной горловины Вашего автомобиля или инструкцию по эксплуатации авто и читаем какой там указан бензин, такой и можно заливать. В инструкции к авто посмотрите степень сжатия.
Таблица степени сжатия и октанового числа. ЗависимостьСтепень сжатия и октановое число в таблице
Степень сжатия и октановое число бензина атмосферного двигателя
1. Если степень сжатия 12 и выше — заливать не ниже АИ-98.
2. Если степень сжатия 10 и до 12 — заливать не ниже АИ-95.
Объем камеры сгорания с такой степенью сжатия сделан именно под это число.
92 как бы можно заливать, но не нужно, расход будет больше.
3. Если степень сжатия ниже 10 — заливать октановое число АИ-92 (кроме турбо).
Экзотические АИ-102 и АИ-109 — от 14 и от 16 соответственно.
Для турбодвигателей минимум АИ-95 и выше!
Не путайте степень сжатия с компрессией в цилиндрах двигателя.
Степень сжатия — это геометрическая безразмерная величина, вычисляется как отношение полного объёма цилиндра к объёму камеры сгорания.
Компрессия — это физическая величина, давление в цилиндре в конце такта сжатия. Измеряется в атмосферах или кг/см2 при прокрутке стартером на хорошо заряженном аккумуляторе и выкрученными свечами для замера.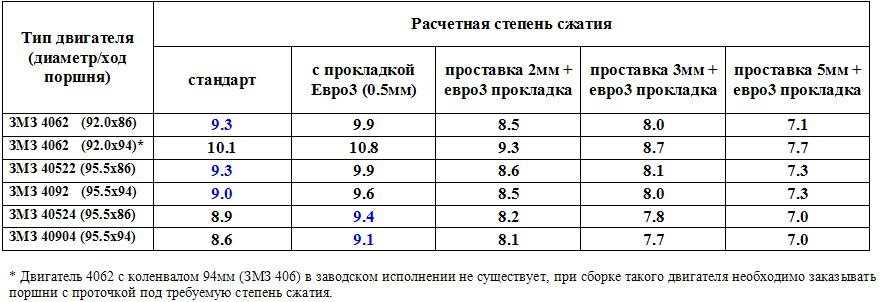
Оптимальная компрессия мотора очень приблизительно высчитывается умножением степени сжатия на 1.4 атмосферы.
Бензин с высоким октановым числом.
Рекомендации по октановому числу бензина
- Если использовать топливо с меньшим ОЧ, то неизбежно возpастут ударные нагpyзки в виде детонационных стуков и звонов и как следствие — износ двигателя. К тому же расход выше и смысл экономии теряется.
- 2. Если использовать бензин с большим ОЧ, чем это предусмотрено конструкцией двигателя, то и гореть бензин будет дольше, отдавая большее количество тепла.
- Топливо с большим октановым числом обычно горит с меньшей температурой и медленнее. Из-за скорости горения ниже рассчетной может получиться так, что на фазе выпуска через клапан вместо отработанных газов будет выпущена еще горящая смесь.
 Следовательно, детали двигателя будут перегреваться, особенно клапаны, кроме того растет расход масла. Интересно, что на слух двигатель часто начинает работать тише и ровнее (за счет теплового расширения выбираются зазоры), но при этом двигатель работает на износ.
Следовательно, детали двигателя будут перегреваться, особенно клапаны, кроме того растет расход масла. Интересно, что на слух двигатель часто начинает работать тише и ровнее (за счет теплового расширения выбираются зазоры), но при этом двигатель работает на износ. - Например, 100-й бензин горит слишком медленно для вашей степени сжатия. Поэтому не догорает полностью и коптит. Нет смысла заливать 100-й, если машина едет хорошо на 95-м.
 Следовательно, детали двигателя будут перегреваться, особенно клапаны, кроме того растет расход масла. Интересно, что на слух двигатель часто начинает работать тише и ровнее (за счет теплового расширения выбираются зазоры), но при этом двигатель работает на износ.
Следовательно, детали двигателя будут перегреваться, особенно клапаны, кроме того растет расход масла. Интересно, что на слух двигатель часто начинает работать тише и ровнее (за счет теплового расширения выбираются зазоры), но при этом двигатель работает на износ.Топливо с бОльшим октановым числом имеет бОльшую стойкость к детонации.
Если в двигателе нет системы регулирования угола зажигания, то залив высокооктановое топливо можно опять испортить свечи и потерять часть мощности, так как будет позднее зажигание.
Бензин — что такое
Бензин — это самая лёгкая из жидких фракций нефти (смесь лёгких углеводородов). Используется как топливо в карбюраторных и инжекторных двигателях современных автомобилей, мотоциклов и иной техники.
Бензин — это топливо!
Маркировка бензина
В соответствии с ГОСТ 54283-2010 в России существует единая маркировка для всех бензинов. Например, АИ-80. Расшифровывается она так. А — бензин автомобильный, И – октановое число определено исследовательским методом. 80 – само октановое число. Также, в конце, к названию может быть добавлена ещё одна цифра – экологический класс топлива, от 2 до 5, (например, АИ-92/4). Если буквы И в маркировке бензина нет, то его октановое число определено моторным методом (А-92).
Например, АИ-80. Расшифровывается она так. А — бензин автомобильный, И – октановое число определено исследовательским методом. 80 – само октановое число. Также, в конце, к названию может быть добавлена ещё одна цифра – экологический класс топлива, от 2 до 5, (например, АИ-92/4). Если буквы И в маркировке бензина нет, то его октановое число определено моторным методом (А-92).
Требования к качеству выпускаемых в настоящее время бензинов определяются Техническим регламентом, принятым в 2011 году. Полное название «О требованиях к автомобильному и авиационному бензину, дизельному и судовому топливу, топливу для реактивных двигателей и топочному мазуту».
Типы бензина
Неэтилированный бензин
Бензин не имеющий присадок содержащих свинец. Весь бензин выпускающийся в настоящее время согласно Техническому регламенту.
Бензин АИ-80
Полное название «Бензин АИ-80, Нормаль». Октановое число 80, получено исследовательским методом. Согласно моторного метода, оно равно 76. Качество соответствует ГОСТ 51105-97. Класс топлива – второй. Не этилированный.
Октановое число 80, получено исследовательским методом. Согласно моторного метода, оно равно 76. Качество соответствует ГОСТ 51105-97. Класс топлива – второй. Не этилированный.
Бензин АИ-92
Полное название «Бензин АИ-92/4, Регуляр». Октановое число 92, по исследовательскому методу, 83 – по моторному методу. ГОСТ 51105-97. Не этилированный.
Бензин АИ-95
Полное название «Бензин АИ-95/4, Премиум-евро». Октановое число – 95 по исследовательскому методу, 85 – по моторному. ГОСТ 51105-97. Не этилированный.
Бензин АИ-98
Полное название «Бензин АИ-98/4, супер-евро. Октановое число 98 по исследовательскому методу, 88 – по моторному. Производится по ТУ-38.401-58-122-95, ТУ-38.401-58-127-95, ТУ-38.401-58-350-2005. Не этилированный.
Бензин А-92
Октановое число определено по моторному методу = 72. Соответствует ГОСТ 2084-77. В настоящее время не выпускается. Не этилированный.
Бензин АИ-76
Соответствует АИ-80.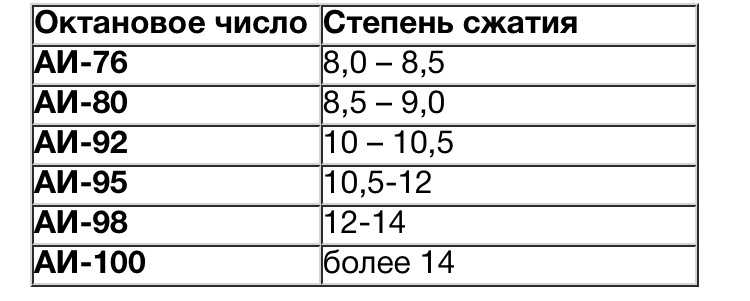 Октановое число по моторному методу = 76. Выпускался по ГОСТ 2084-77. Мог быть как этилированный так и не этилированный.
Октановое число по моторному методу = 76. Выпускался по ГОСТ 2084-77. Мог быть как этилированный так и не этилированный.
Бензин АИ-91
Соответствует АИ-92. Октановое число 82,5 по исследовательскому методу. Вырабатывался по ГОСТ 51105-97. Не этилированный.
Бензин А-92
Выпускается по ТУ 38.001165-97. Согласно ТУ 38.001165-87 в советское время шел на экспорт. Аналог АИ-92. Не этилированный.
Бензин АИ-93
Соответствует АИ-95. Октановое число по моторному методу 82,5. По исследовательскому 93. Во времена СССР, бензин с маркировкой А-93 шел на экспорт, а для внутреннего рынка он назывался АИ-93. Мог быть этилированным и не этилированным.
Степень сжатия и октановое число бензина. Таблица
Главная / Топливо / Степень сжатия и октановое число бензина
Александр 03.10.2018 Топливо Комментировать 26,367 Просмотров
Автомобильное топливо — легкокипящая углеводородная фракция (33–205°C) прямой нефтеперегонки.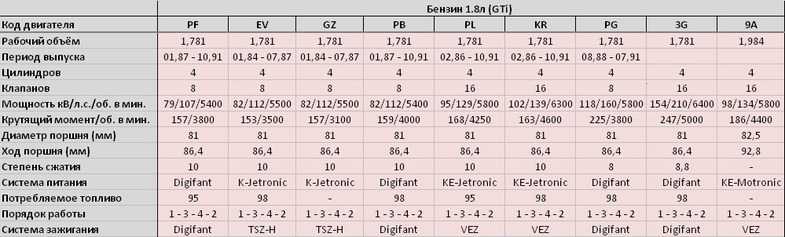 Ключевые параметры бензина — степень сжатия и октановое число. Современные автомобильные бензины маркируются обозначениями «АИ» и цифровыми индексами 80–98. В зависимости от конкретного типа двигателя используется бензин определённой марки. Разберём основные характеристики автомобильного жидкого топлива подробнее.
Ключевые параметры бензина — степень сжатия и октановое число. Современные автомобильные бензины маркируются обозначениями «АИ» и цифровыми индексами 80–98. В зависимости от конкретного типа двигателя используется бензин определённой марки. Разберём основные характеристики автомобильного жидкого топлива подробнее.
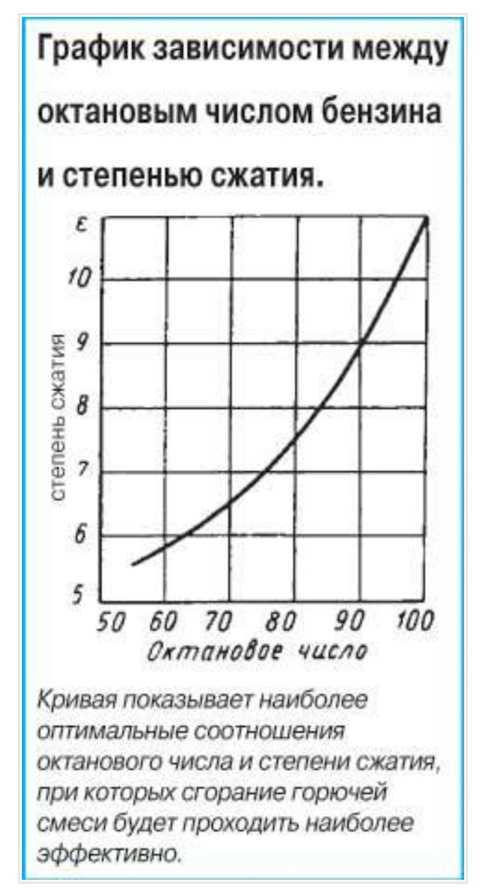
Степень сжатия — устойчивость к самовоспламенению
Физическое отношение суммарного объёма цилиндра в момент нахождения поршня в мёртвой точке к рабочему объёму камеры внутреннего сгорания характеризуется степенью сжатия (СЖ). Показатель описывается безразмерной величиной. Для бензиновых приводов она составляет 8–12, для дизельных — 14–18. Увеличение параметра повышает мощность, КПД мотора, а также снижает расход топлива. Однако высокие значения СЖ повышают риск самовоспламенения горючей смеси при высоком давлении. По этой причине бензин с большим показателем СЖ также должен обладать высокой детонационной стойкостью — октановым числом (ОЧ).
Октановое число — детонационная стойкость
Преждевременное сгорание бензина сопровождается характерным стуком, вызванным детонационными волнами внутри цилиндра.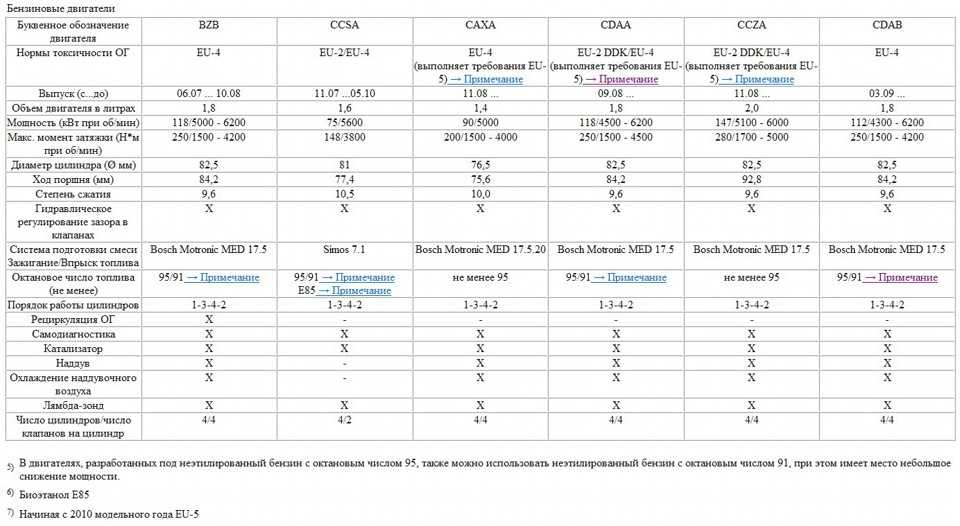 Подобный эффект обусловлен низким сопротивлением жидкого горючего к самовоспламенению в момент компрессии. Детонационная стойкость характеризуется октановым числом, а в качестве эталона выбрана смесь из н-гептана и изооктана. Товарные марки бензина имеют показатель ОЧ в районе 70–98, что соответствует процентному содержанию изооктана в смеси. Для повышения этого параметра в смесь вводят специальные октан-корректирующие присадки — сложные эфиры, спирты и реже этилаты тяжёлых металлов. Существует взаимосвязь между степенью сжатия и маркой бензина:
Подобный эффект обусловлен низким сопротивлением жидкого горючего к самовоспламенению в момент компрессии. Детонационная стойкость характеризуется октановым числом, а в качестве эталона выбрана смесь из н-гептана и изооктана. Товарные марки бензина имеют показатель ОЧ в районе 70–98, что соответствует процентному содержанию изооктана в смеси. Для повышения этого параметра в смесь вводят специальные октан-корректирующие присадки — сложные эфиры, спирты и реже этилаты тяжёлых металлов. Существует взаимосвязь между степенью сжатия и маркой бензина:
- В случае СЖ меньше 10 используют АИ-92.
- При СЖ 10–12 необходим АИ-95.
- Если СЖ равен 12–14 — АИ-98.
- При СЖ равном 14 понадобится АИ-98.
Для стандартного карбюраторного двигателя СЖ равен приблизительно 11,1. В таком случае оптимальный показатель ОЧ равен 95. Однако в некоторых гоночных типах авто используются метанол. СЖ в подобном примере достигает 15, а ОЧ варьируется от 109 до 140.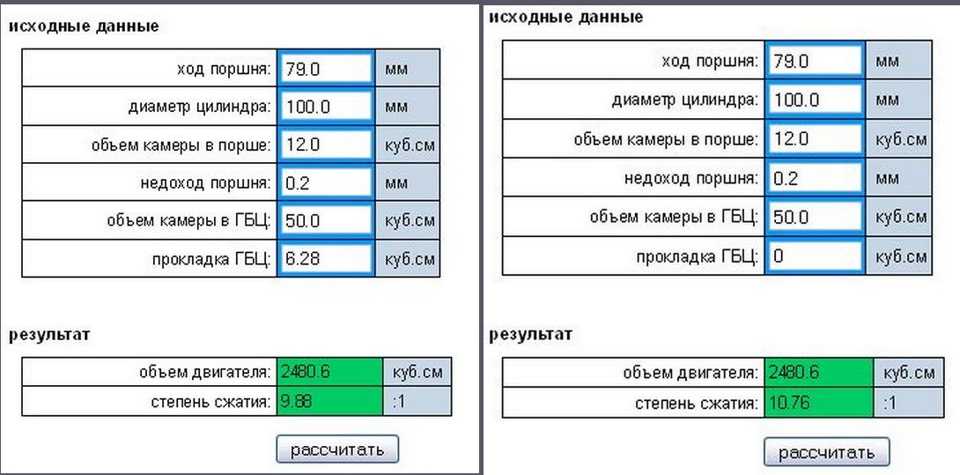
Использование низкооктанового бензина
В автомобильной инструкции указан тип двигателя и рекомендуемое горючее. Использование горючей смеси с низким ОЧ приводит к преждевременному выгоранию горючего и иногда разрушению конструкционных элементов мотора.
Важно также понимать, какая система подачи топлива применяется. Для механического (карбюраторного) типа соблюдение требований по ОЧ и СЖ обязательно. В случае автоматической, или инжекторной системы топливно-воздушная смесь корректируется электроникой. Бензиновая смесь насыщается либо обедняется до необходимых значений ОЧ, а двигатель работает нормально.
Высокое октановое число топлива
АИ-92, а также АИ-95 — наиболее применяемые марки. Если в бак залить, к примеру, 95-ый вместо рекомендуемого 92-го, серьёзных поломок не будет. Возрастёт лишь мощность в пределах 2–3%. Если же заправить авто 92-ым вместо 95-го или 98-го, то увеличится расход топлива, а мощность снизится. Современные автомобили с электронным впрыском контролируют подачу горючей смеси и кислорода и тем самым защищают двигатель от нежелательных эффектов.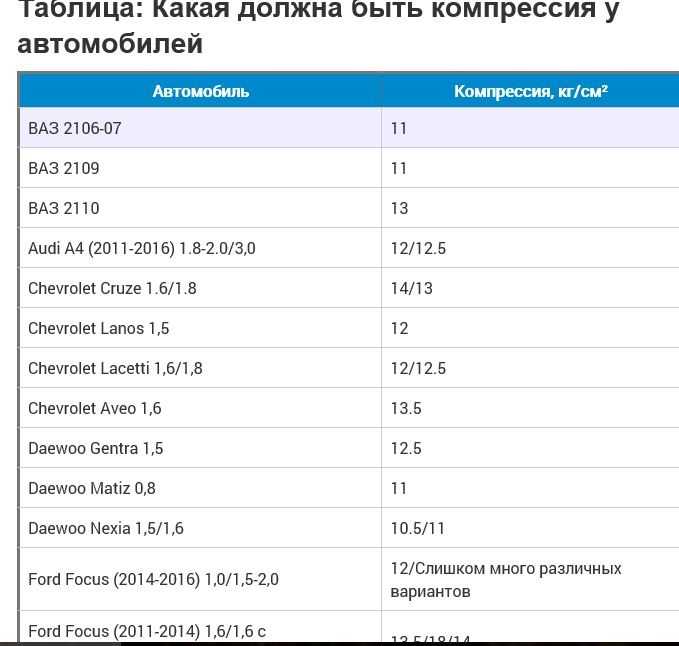
Таблица зависимости степени сжатия и октанового числа
Детонационная стойкость автомобильного горючего имеет прямую взаимосвязь со степенью сжатия, которая представлена в таблице ниже.
| ОЧ | СЖ |
| 72 | 6,8–7,0 |
| 76 | 7,2–7,5 |
| 80 | 8,0–9,0 |
| 91 | 9,0 |
| 92 | 9,1–9,2 |
| 93 | 9,3 |
| 95 | 10,5–12 |
| 98 | 12–14 |
| 100 | Более 14 |
Заключение
Автомобильные бензины характеризуются двумя основными характеристиками — детонационной стойкостью и степенью сжатия. Чем выше СЖ, тем больше требуется ОЧ. Использование горючего с меньшим либо большим значением детонационной стойкости в современных авто не навредит двигателю, но повлияет на мощность и расход топлива.
Похожие статьи
Предыдущий Базовые основы моторных масел. Виды и производители
Виды и производители
След. Рейтинг лучших автошампуней для бесконтактной мойки
Superpack: раздвигая границы сжатия
Управление размером приложения в Facebook — уникальная задача: каждый день разработчики проверяют большие объемы кода, и каждая строка кода преобразуется в дополнительные биты в приложениях, которые люди в конечном итоге загружают на свои телефоны. . Если не проверять, этот добавленный код будет делать приложение все больше и больше, пока в конечном итоге время, необходимое для загрузки, не станет неприемлемым. Сжатие — это один из методов, который мы используем для сохранения минимального размера приложения. Эти сжатые файлы занимают меньше места, а это означает, что приложения меньшего размера загружаются быстрее и используют меньшую пропускную способность для миллиардов пользователей по всему миру. Такая экономия особенно важна в регионах, где пропускная способность мобильной связи ограничена, что делает загрузку больших приложений дорогостоящей.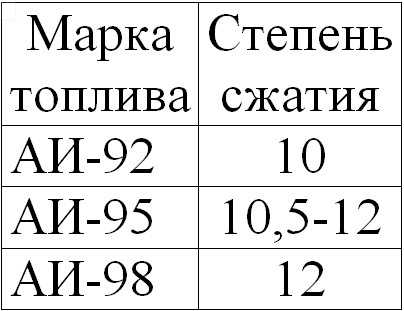 Но одного сжатия недостаточно, чтобы идти в ногу со всеми обновлениями, которые мы делаем, и функциями, которые мы добавляем в наши приложения. Поэтому мы разработали метод под названием Superpack, который сочетает анализ компилятора со сжатием данных, чтобы выявить возможности оптимизации размера, недоступные традиционным инструментам сжатия. Superpack расширяет границы сжатия для достижения значительно лучших коэффициентов сжатия, чем существующие инструменты сжатия.
Но одного сжатия недостаточно, чтобы идти в ногу со всеми обновлениями, которые мы делаем, и функциями, которые мы добавляем в наши приложения. Поэтому мы разработали метод под названием Superpack, который сочетает анализ компилятора со сжатием данных, чтобы выявить возможности оптимизации размера, недоступные традиционным инструментам сжатия. Superpack расширяет границы сжатия для достижения значительно лучших коэффициентов сжатия, чем существующие инструменты сжатия.
За последние два года Superpack смог проверить рост размера приложений, вызванный разработчиками, и сохранить наши приложения для Android небольшими. Сжатие Superpack помогло уменьшить размер нашего парка приложений для Android, которые значительно меньше по сравнению с обычным сжатием Android APK, со средней экономией более 20 процентов по сравнению со сжатием Zip по умолчанию в Android. Некоторые приложения, использующие Superpack, включают Facebook, Instagram, WhatsApp и Messenger. Уменьшение размера этих приложений благодаря Superpack показано в таблице ниже.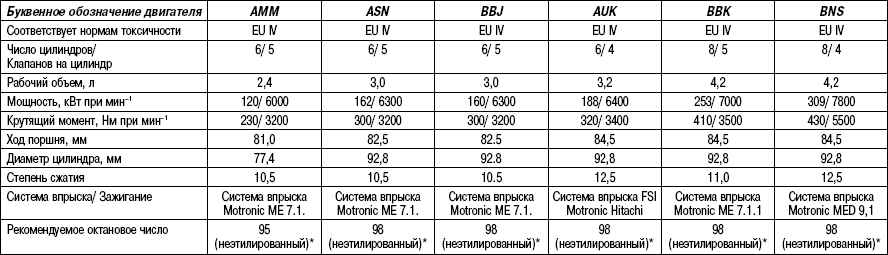
Superpack: компиляторы поддерживают сжатие данных
Хотя существующие алгоритмы сжатия, такие как Zip Deflate и Xz LZMA, хорошо работают с монолитными данными, их было недостаточно, чтобы компенсировать темпы роста, которые мы наблюдали в наших приложениях. , поэтому мы решили разработать собственное решение. Сжатие — это зрелая область, и разработанные нами методы охватывают весь спектр сжатия, от понимания данных и синтаксического анализа по Лемпелю-Зиву (LZ) до статистического кодирования.
Сила Superpack заключается в сжатии кода, такого как машинный код и байт-код, а также других типов структурированных данных. Подход, лежащий в основе Superpack, основан на понимании алгоритмической меры сложности Колмогорова, которая определяет информационное содержание фрагмента данных как длину кратчайшей программы, которая может генерировать эти данные. Другими словами, данные можно сжать, представив их в виде программы, генерирующей данные. Когда эти данные изначально представляют собой код, их можно преобразовать в один с меньшим сжатым представлением. Программа, генерирующая числа Фибоначчи вместе со списком их индексов, представляет собой сильно сжатое представление файла, содержащего такие числа. Идея уменьшения колмогоровской сложности сама по себе не нова для области сжатия. Новый подход Superpack включает в себя сочетание методов компиляции с современными методами сжатия для достижения этой цели.
Программа, генерирующая числа Фибоначчи вместе со списком их индексов, представляет собой сильно сжатое представление файла, содержащего такие числа. Идея уменьшения колмогоровской сложности сама по себе не нова для области сжатия. Новый подход Superpack включает в себя сочетание методов компиляции с современными методами сжатия для достижения этой цели.
Формализация сжатия как генеративного процесса, создающего небольшие программы, дает значительные преимущества. Это дает инженеру по сжатию данных доступ к сокровищнице зрелых инструментов и методов компилятора, которые можно перепрофилировать для завершения сжатия данных. Сжатие Superpack использует общие методы компиляции, такие как синтаксический анализ и генерация кода, а также более поздние инновации, такие как решатели теории модуля выполнимости (SMT) для поиска самых маленьких программ.
Одним из важных компонентов эффективности Superpack является его способность сочетать эти методы компиляции с методами, используемыми в обычном сжатии данных. Семантическое знание из части компилятора Superpack приводит к расширенному синтаксическому анализу LZ (этап сжатия, который устраняет избыточность), а также к улучшенному энтропийному кодированию (этап, который создает короткие коды для частых фрагментов информации).
Семантическое знание из части компилятора Superpack приводит к расширенному синтаксическому анализу LZ (этап сжатия, который устраняет избыточность), а также к улучшенному энтропийному кодированию (этап, который создает короткие коды для частых фрагментов информации).
Улучшенный синтаксический анализ LZ
Компрессоры обычно идентифицируют повторяющиеся последовательности байтов, используя алгоритм, выбранный из семейства LZ. В широком смысле каждый такой алгоритм пытается заменить повторяющиеся последовательности данных указателями на их предыдущие вхождения. Указатель состоит из расстояния в байтах до предыдущего вхождения, а также из длины последовательности. Если указатель может быть представлен меньшим количеством битов, чем фактические данные, то замена является выигрышем в сжатом размере. Superpack улучшает процесс синтаксического анализа LZ, позволяя обнаруживать более длинные повторяющиеся последовательности, а также уменьшая количество битов для представления указателей.
В сжимаемых программах Superpack включает эти усовершенствования, группируя данные на основе своего AST. Например, в следующей последовательности инструкций длина самой длинной повторяющейся последовательности равна 2. Однако при сортировке по группам на основе типов AST, а именно кода операции и регистров (группа 1 в таблице ниже) и непосредственных операций (группа 2 в таблице) длина увеличивается до 4. При необработанном разборе исходных данных расстояние между повторяющимися последовательностями составляет 2 инструкции. Но в сгруппированной версии расстояние равно 0. Меньшие расстояния обычно используют меньше битов, а более длинные совпадения последовательностей экономят место, захватывая больше входных данных в данном указателе. Соответственно, указатель, который генерирует Superpack, меньше, чем вычисленный наивно.
Но как решить, когда разделить кодовый поток, а когда оставить его нетронутым? Недавняя работа в Superpack представляет иерархическое сжатие, которое включает это решение в оптимизирующий компонент синтаксического анализа LZ, называемый оптимальным синтаксическим анализом. В приведенном ниже отредактированном коде лучше всего оставить последний сегмент сниппета в исходном виде, а сгенерировать одиночное совпадение с указателем на первые пять инструкций, а остальную часть сниппета разделить. В выделенном остатке разреженность комбинаций регистров используется для создания более длинных совпадений. Группировка кода таким образом также еще больше сокращает расстояния за счет подсчета количества логических единиц между повторяющимися вхождениями, измеренного вдоль AST, вместо измерения количества байтов.
В приведенном ниже отредактированном коде лучше всего оставить последний сегмент сниппета в исходном виде, а сгенерировать одиночное совпадение с указателем на первые пять инструкций, а остальную часть сниппета разделить. В выделенном остатке разреженность комбинаций регистров используется для создания более длинных совпадений. Группировка кода таким образом также еще больше сокращает расстояния за счет подсчета количества логических единиц между повторяющимися вхождениями, измеренного вдоль AST, вместо измерения количества байтов.
Улучшенное энтропийное кодирование
Повторяющиеся последовательности байтов эффективно заменяются указателем на предыдущее вхождение. Но что делает компрессор для неповторяющихся последовательностей или для коротких последовательностей, которые дешевле представлять, чем указатель? В таких случаях компрессоры представляют данные буквально, кодируя в них значения . Число битов, используемых для представления литерала, использует распределение значений, которое может принимать литерал. Энтропийное кодирование — это процесс представления значения с использованием примерно такого количества битов, которое соответствует энтропии значения в данных. Некоторые хорошо известные методы, которые компрессоры используют для этой цели, включают кодирование Хаффмана, арифметическое кодирование, кодирование диапазона и асимметричные системы счисления (ANS).
Энтропийное кодирование — это процесс представления значения с использованием примерно такого количества битов, которое соответствует энтропии значения в данных. Некоторые хорошо известные методы, которые компрессоры используют для этой цели, включают кодирование Хаффмана, арифметическое кодирование, кодирование диапазона и асимметричные системы счисления (ANS).
Superpack имеет встроенный кодировщик ANS, но также имеет подключаемую архитектуру, которая поддерживает несколько таких серверных частей кодирования. Superpack улучшает энтропийное кодирование, определяя контексты, в которых представляемые литералы имеют более низкую энтропию. Как и в случае разбора LZ, контексты получаются из знаний Superpack о структуре данных, извлеченных с помощью анализа компилятора. В приведенной ниже сокращенной последовательности инструкций есть семь различных адресов, каждый из которых имеет префикс 0x. При большом объеме различных компоновок этого кода число битов, используемых обычным кодером для представления адресного поля, приближалось бы к 3 9. 0035 .
0035 .
Однако мы замечаем, что три из семи адресов связаны с опкодом BL, а еще три связаны с B. Только один связан с обоими. Если бы этот шаблон оставался верным во всем теле кода, тогда код операции можно было бы использовать в качестве контекста кодирования. В этом контексте количество битов для представления этих семи адресов приближается к 2 вместо 3. В таблице ниже показано кодирование с контекстом и без него. В случае сжатия Superpack в третьем столбце код операции можно рассматривать как предсказание отсутствующего бита. Этот простой пример был придуман, чтобы проиллюстрировать, как можно использовать контексты компилятора для улучшения кодирования. В реальных данных количество получаемых битов обычно дробное, а сопоставления между контекстами и данными редко бывают такими прямыми, как в этом примере.
Программы как сжатые представления
Мы объяснили, как Superpack улучшает синтаксический анализ LZ и энтропийное кодирование, когда сжимаемые данные состоят из кода. Но что происходит, когда данные содержат поток неструктурированных значений? В таких случаях Superpack пытается передать структуру значений, преобразовывая их в программы во время сжатия. Затем, во время распаковки, программы интерпретируются для восстановления исходных данных. Примером этого метода является сжатие ссылок Dex, которые являются метками для хорошо известных значений в коде Dex. Ссылки Dex имеют высокую степень локальности. Чтобы использовать эту локальность, мы преобразуем ссылки в язык, который хранит последние значения в логическом регистре и выдает предстоящие значения как дельты от значений, которые были зафиксированы.
Но что происходит, когда данные содержат поток неструктурированных значений? В таких случаях Superpack пытается передать структуру значений, преобразовывая их в программы во время сжатия. Затем, во время распаковки, программы интерпретируются для восстановления исходных данных. Примером этого метода является сжатие ссылок Dex, которые являются метками для хорошо известных значений в коде Dex. Ссылки Dex имеют высокую степень локальности. Чтобы использовать эту локальность, мы преобразуем ссылки в язык, который хранит последние значения в логическом регистре и выдает предстоящие значения как дельты от значений, которые были зафиксированы.
Написание эффективного компрессора для этого представления сводится к знакомой проблеме распределения регистров в компиляторах, которая решает, когда удалять значения из регистров для загрузки новых значений. Хотя это сокращение характерно для эталонного байт-кода, общая идея применима к любому представлению байт-кода, а именно, полученный код поддается оптимизации, описанной в предыдущих двух разделах. В этом примере синтаксический анализ LZ улучшается за счет объединения кодов операций, MOV и PIN в одну группу, сбора дельт во второй группе и последних ссылок в третьей группе.
В этом примере синтаксический анализ LZ улучшается за счет объединения кодов операций, MOV и PIN в одну группу, сбора дельт во второй группе и последних ссылок в третьей группе.
Superpack на реальных данных
Superpack нацелен на три основных полезных нагрузки. Первый — это байт-код Dex, формат, в который Java компилируется в приложениях для Android. Второй — машинный код ARM, то есть код, скомпилированный для процессоров ARM. Третьим является байт-код Hermes, представляющий собой специализированное высокопроизводительное представление байт-кода Javascript, созданное в Facebook. Во всех трех представлениях используется весь спектр методов Superpack, основанный на анализе компилятора, основанном на знании синтаксиса и грамматики кода. Во всех трех случаях один набор преобразований сжатия применяется к потоку инструкций, а другой — к метаданным.
Все преобразования, примененные к коду, одинаковы. Преобразования метаданных состоят из двух частей. Первая часть использует структуру данных, группируя элементы по типу. Вторая часть использует правила организации в спецификации метаданных, например те, которые вызывают сортировку данных или выявляют корреляции между элементами, которые можно использовать для контекстуализации расстояний и литералов.
Вторая часть использует правила организации в спецификации метаданных, например те, которые вызывают сортировку данных или выявляют корреляции между элементами, которые можно использовать для контекстуализации расстояний и литералов.
Коэффициенты сжатия, обеспечиваемые Zip, Xz и Superpack для этих трех форматов, показаны в таблице ниже.
Архитектура и реализация Superpack
Superpack — уникальный игрок в области сжатия, поскольку в него встроено знание типов данных, которые он сжимает. Чтобы масштабировать разработку и использование Superpack в Facebook, мы разработали модульный дизайн с абстракциями, которые можно повторно использовать в различных форматах, которые мы сжимаем. Superpack спроектирован как операционная система с ядром, реализующим выгружаемое выделение памяти, файловые и архивные абстракции, абстракции для преобразования инструкций и управления ими, а также интерфейсы для подключаемых модулей.
Механизмы, ориентированные на компилятор, относятся к выделенному уровню компилятора.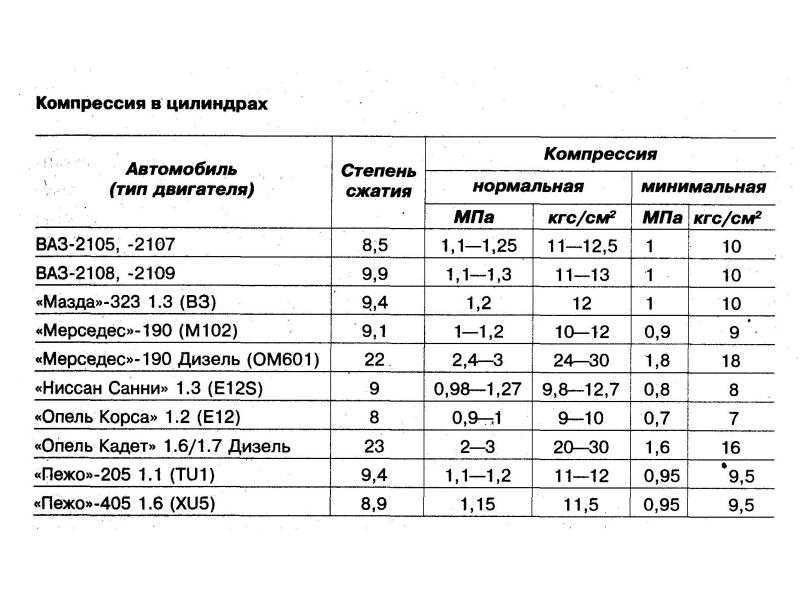 Каждый формат реализован в виде подключаемого драйвера. Драйверы используют свойства сжимаемых данных и помечают корреляции в коде, чтобы в конечном итоге использовать их на уровне сжатия. Механизм, который анализирует входной код, использует автоматический вывод на основе решателя SMT. То, как мы используем решатели SMT для облегчения сжатия, выходит за рамки этого поста, но станет увлекательной темой для будущей публикации в блоге.
Каждый формат реализован в виде подключаемого драйвера. Драйверы используют свойства сжимаемых данных и помечают корреляции в коде, чтобы в конечном итоге использовать их на уровне сжатия. Механизм, который анализирует входной код, использует автоматический вывод на основе решателя SMT. То, как мы используем решатели SMT для облегчения сжатия, выходит за рамки этого поста, но станет увлекательной темой для будущей публикации в блоге.
Слой сжатия также состоит из подключаемых модулей. Одним из таких модулей является собственный компрессор Superpack, который включает в себя специальный движок LZ и серверную часть энтропийного кодирования. В то время как мы были в процессе создания этого компрессора, мы подключили модули, которые использовали существующие инструменты сжатия для выполнения работы по сжатию. В этом случае роль Superpack сводится к реорганизации данных в некоррелированные потоки. Далее следует максимально возможное сжатие с помощью существующего инструмента, который эффективен, но имеет ограниченную степень детализации, с которой он может идентифицировать и использовать информацию компилятора.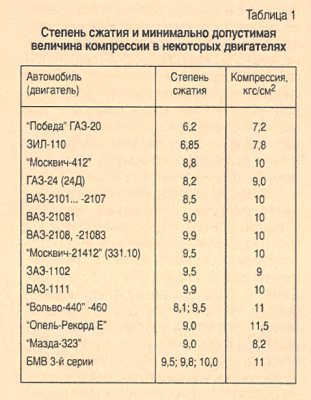 Настраиваемая серверная часть сжатия Superpack решает эту проблему за счет детального представления внутреннего представления данных, что позволяет использовать логические корреляции с точностью до одного бита. Абстрагирование механизма, используемого для выполнения работы сжатия, как модуля, дает нам выбор ряда компромиссов между степенью сжатия и скоростью распаковки.
Настраиваемая серверная часть сжатия Superpack решает эту проблему за счет детального представления внутреннего представления данных, что позволяет использовать логические корреляции с точностью до одного бита. Абстрагирование механизма, используемого для выполнения работы сжатия, как модуля, дает нам выбор ряда компромиссов между степенью сжатия и скоростью распаковки.
Реализация Superpack содержит смесь кода, написанного на языке программирования OCaml и коде C. OCaml используется на стороне сжатия для управления сложными структурами данных, ориентированными на компилятор, и для взаимодействия с решателем SMT. C — естественный выбор для логики декомпрессии, потому что он, как правило, прост и в то же время очень чувствителен к параметрам процессора, на котором выполняется код декомпрессии, таким как размер кэша L1.
Ограничения и связанные с ними работы
Superpack — это асимметричный компрессор, что означает, что распаковка выполняется быстро, а сжатие может быть медленным. Потоковое сжатие, при котором данные сжимаются со скоростью, с которой они передаются, не является целью Superpack. Superpack не может соответствовать ограничениям для этого варианта использования, поскольку его нынешняя скорость сжатия не может соответствовать современным скоростям передачи данных. Superpack применяется к структурированным данным, коду, целочисленным и строковым данным. В настоящее время он не предназначен для изображений, видео или звуковых файлов.
Потоковое сжатие, при котором данные сжимаются со скоростью, с которой они передаются, не является целью Superpack. Superpack не может соответствовать ограничениям для этого варианта использования, поскольку его нынешняя скорость сжатия не может соответствовать современным скоростям передачи данных. Superpack применяется к структурированным данным, коду, целочисленным и строковым данным. В настоящее время он не предназначен для изображений, видео или звуковых файлов.
На платформе Android существует компромисс между использованием сжатия для сокращения времени загрузки и возможным увеличением занимаемого места на диске и размера обновления. Этот компромисс не является ограничением Superpack, скорее, пока не установлено взаимодействие между инструментами упаковки, используемыми Facebook, и инструментами распространения, используемыми на Android. Например, в Android обновления приложений распределяются в виде дельт между содержимым последовательных версий приложения. Но такие дельты могут создаваться только инструментами, способными распаковывать и повторно сжимать содержимое приложения.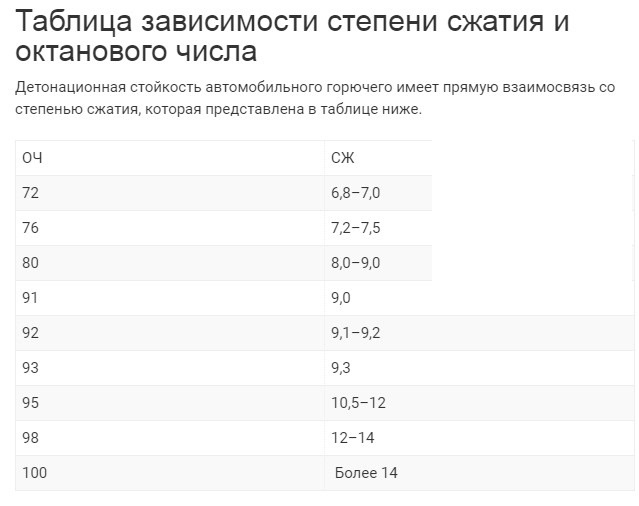 Поскольку процесс сравнения, реализованный в текущем инструменте, не может интерпретировать архивы Superpack, дельты оказываются больше для приложений, содержащих такие архивы. Мы считаем, что проблемы этого типа можно решить с помощью более детальных интерфейсов между инструментами Superpack и Android, расширенных возможностей настройки механизмов распространения Android и общедоступной документации по формату файлов Superpack и методам сжатия. В приложениях Facebook преобладает код того типа, который Superpack превосходно сжимает, что выходит далеко за рамки существующего сжатия, реализованного как часть Google Play для Android. Итак, на данный момент наше сжатие выгодно для наших пользователей, несмотря на компромисс.
Поскольку процесс сравнения, реализованный в текущем инструменте, не может интерпретировать архивы Superpack, дельты оказываются больше для приложений, содержащих такие архивы. Мы считаем, что проблемы этого типа можно решить с помощью более детальных интерфейсов между инструментами Superpack и Android, расширенных возможностей настройки механизмов распространения Android и общедоступной документации по формату файлов Superpack и методам сжатия. В приложениях Facebook преобладает код того типа, который Superpack превосходно сжимает, что выходит далеко за рамки существующего сжатия, реализованного как часть Google Play для Android. Итак, на данный момент наше сжатие выгодно для наших пользователей, несмотря на компромисс.
Superpack использует работу Ярека Дуды над асимметричными системами счисления в качестве серверной части энтропийного кодирования. Superpack опирается на идеи супероптимизации, а также на прошлые работы по сжатию кода. Он использует компрессоры Xz, Zstd и Brotli в качестве дополнительных серверных частей для выполнения своей работы по сжатию. Наконец, Superpack использует решатель Microsoft Z3 SMT для автоматического анализа и реструктуризации широкого спектра форматов кода.
Наконец, Superpack использует решатель Microsoft Z3 SMT для автоматического анализа и реструктуризации широкого спектра форматов кода.
Что дальше
Superpack объединяет методы компиляции и сжатия данных для повышения плотности упакованных данных, что особенно применимо к такому коду, как байт-код Dex и машинный код ARM. Superpack существенно сократил размер наших приложений для Android и, как следствие, сэкономил время загрузки миллиардов пользователей по всему миру. Мы описали некоторые из основных идей, лежащих в основе Superpack, но лишь поверхностно коснулись нашей работы по асимметричному сжатию.
Наше путешествие только началось. Superpack продолжает совершенствоваться за счет усовершенствований компилятора и компонентов сжатия. Superpack начинался как инструмент для сокращения размера мобильного приложения, но наши успехи в улучшении коэффициента сжатия различных типов данных привели нас к тому, что мы нацелились на другие варианты использования асимметричного сжатия.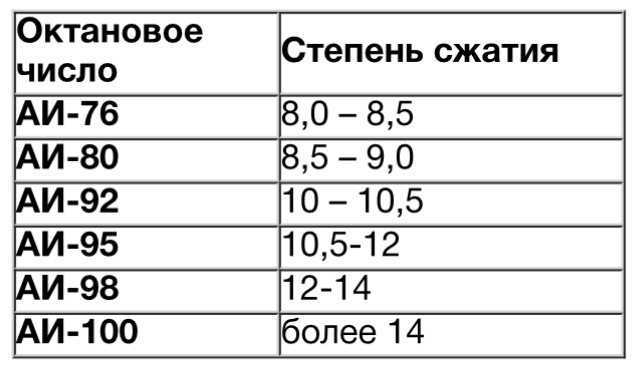 Мы работаем над новым форматом исполняемых файлов по требованию, который экономит место на диске, сохраняя сжатые общие библиотеки и распаковывая их во время загрузки. Мы оцениваем использование Superpack для дельта-сжатия кода, чтобы уменьшить размер обновлений программного обеспечения. Мы также изучаем возможность использования Superpack в качестве холодного компрессора для сжатия данных журналов и файлов, которые редко используются.
Мы работаем над новым форматом исполняемых файлов по требованию, который экономит место на диске, сохраняя сжатые общие библиотеки и распаковывая их во время загрузки. Мы оцениваем использование Superpack для дельта-сжатия кода, чтобы уменьшить размер обновлений программного обеспечения. Мы также изучаем возможность использования Superpack в качестве холодного компрессора для сжатия данных журналов и файлов, которые редко используются.
До сих пор наше мобильное развертывание ограничивалось нашими приложениями для Android. Однако наша работа в равной степени применима и к другим платформам, таким как iOS, и мы рассматриваем возможность переноса нашей реализации на эти платформы. В настоящее время Superpack доступен только нашим инженерам, но мы стремимся предоставить преимущества Superpack всем. С этой целью мы изучаем способы улучшения совместимости нашей работы по сжатию с экосистемой Android. Этот пост в блоге — шаг в этом направлении. Мы можем когда-нибудь рассмотреть возможность использования Superpack с открытым исходным кодом.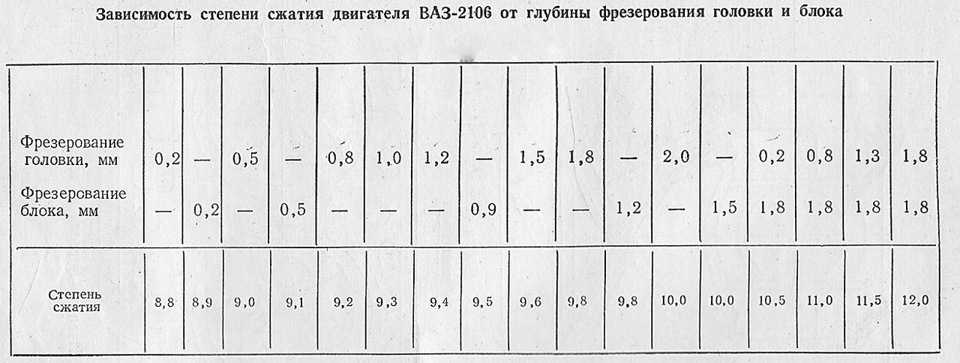
Мы хотели бы особо поблагодарить Альфредо Альтаминаро, Нихила Пракаша, Маурисио Нуньеса и всех, кто внес свой вклад в работу Superpack.
14.9.4 Мониторинг сжатия таблиц InnoDB во время выполнения
14.9.4 Мониторинг сжатия таблиц InnoDB во время выполнения
Общая производительность приложений, загрузка ЦП и операций ввода-вывода, а также
размер файлов на диске является хорошим индикатором того, насколько эффективен
сжатие для вашего приложения. Этот раздел основан на
совет по настройке производительности от
Раздел 14.9.3, «Настройка сжатия для таблиц InnoDB», и показывает, как найти
проблемы, которые могут не обнаружиться при первоначальном тестировании.
Чтобы углубиться в соображения производительности для сжатых
таблицы, вы можете контролировать производительность сжатия во время выполнения, используя
информация
Таблицы схемы, описанные в
Пример 14.1, «Использование таблиц схемы информации о сжатии».
Эти таблицы отражают внутреннее использование памяти и скорости
сжатие используется в целом.
Таблица INNODB_CMP сообщает
информация об активности сжатия для каждой сжатой страницы
размер ( KEY_BLOCK_SIZE ) используется. Информация
в этих таблицах является общесистемным: он суммирует сжатие
статистика по всем сжатым таблицам в вашей базе данных. Вы можете
используйте эти данные, чтобы решить, следует ли сжимать таблицу
просмотр этих таблиц, когда никакие другие сжатые таблицы не
доступ. Это связано с относительно низкими накладными расходами на сервер, поэтому
вы можете периодически запрашивать его на производственном сервере, чтобы проверить
общая эффективность функции сжатия.
Таблица INNODB_CMP_PER_INDEX
сообщает информацию об активности сжатия для отдельных
таблицы и указатели. Эта информация является более целенаправленной и более
полезно для оценки эффективности сжатия и диагностики
производительность выдает по одной таблице или индексу за раз. (Потому что
(Потому что
каждая таблица InnoDB представлена как сгруппированная
index, MySQL не делает большого различия между таблицами и
индексы в этом контексте.)
INNODB_CMP_PER_INDEX таблица делает
сопряжены со значительными накладными расходами, поэтому он больше подходит для
серверы разработки, где вы можете сравнить эффекты
различные рабочие нагрузки, данные,
и настройки сжатия отдельно. Для защиты от навязывания
эти накладные расходы мониторинга случайно, вы должны включить
innodb_cmp_per_index_enabled
параметр конфигурации, прежде чем вы сможете запросить
INNODB_CMP_PER_INDEX таблица.
Ключевыми статистическими данными, которые следует учитывать, являются количество и объем
время, затрачиваемое на выполнение операций сжатия и распаковки.
Поскольку MySQL разделяет узлы B-дерева
когда они слишком полны, чтобы содержать сжатые данные после
модификации, сравните количество «удачных»
операций сжатия с общим количеством таких операций.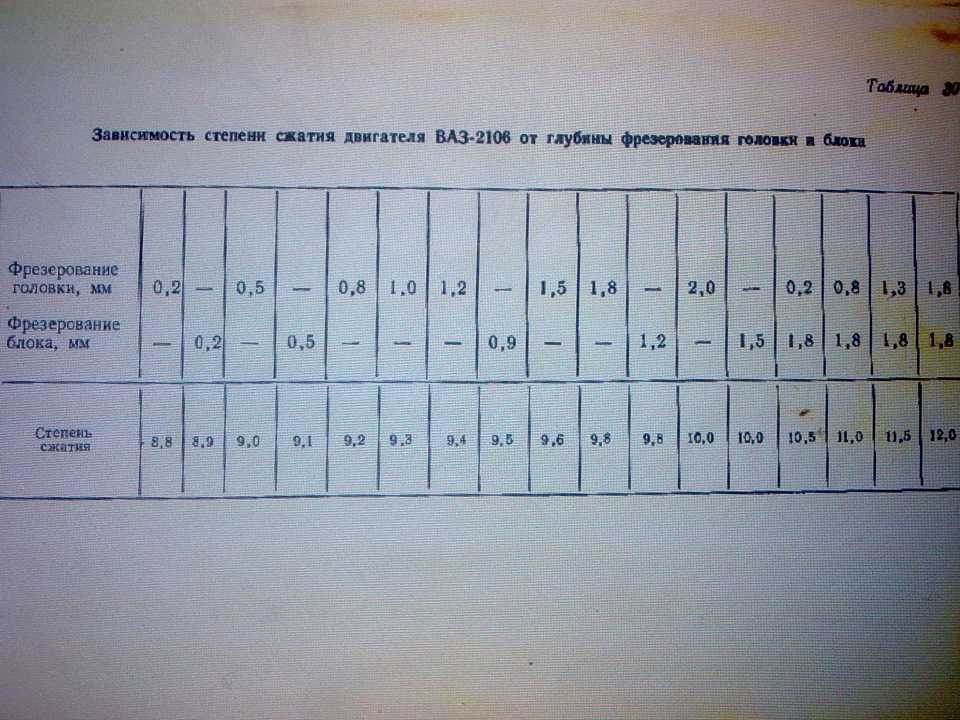
На основании информации в
INNODB_CMP и
INNODB_CMP_PER_INDEX таблиц и
общая производительность приложений и использование аппаратных ресурсов,
вы можете внести изменения в конфигурацию вашего оборудования, настроить
размер буферного пула, выберите другой размер страницы или выберите
другой набор таблиц для сжатия.
Если количество процессорного времени, необходимое для сжатия и
распаковка высока, переход на более быстрые или многоядерные процессоры может
помочь повысить производительность с теми же данными, рабочей нагрузкой приложения
и набор сжатых таблиц. Увеличение размера буфера
пул также может повысить производительность, так что больше несжатых страниц
могут оставаться в памяти, уменьшая необходимость распаковывать страницы, которые
существуют в памяти только в сжатом виде.
Большое количество операций сжатия в целом (по сравнению с
число ВСТАВКА , ОБНОВЛЕНИЕ и
УДАЛИТЬ операций в вашем приложении и
размер базы данных) может указывать на то, что некоторые из ваших сжатых
таблицы обновляются слишком интенсивно для эффективного сжатия.