Содержание
Настройка КПП, машины с чарджером в Drag racing: Уличные гонки
Чтобы посмотреть видео гайд, кликните по изображению выше.
Описание видео гайда
Всем привет! В последнее время вы меня очень просили рассказать о том, как правильно настроить авто на чарджере. Именно поэтому в этом видео гайде вы узнаете о том, каким способом правильно выполнять настройку КПП, коробки передач и машины с чарджером в целом в мобильной игре Drag racing: Уличные гонки.
Текст видео гайда (субтитры)
Здорова братишки в самом в начале хотел бы всех поблагодарить за 10000 подписчиков спасибо вам огромное спасибо за то что смотрите лайкайте и подписывайтесь и также отдельное спасибо ребятам, который до сих пор продолжает помогать не подключить волоконный интернет посредством доната спасибо огромное братишки за вашу поддержку ну и сегодня по вашим многочисленным просьбам я покажу как настраивать автомобиль дача geely погнали.
Итак, ребята, я специально включил захват курсора мыши, чтобы более правильно и подробно вам все показать, поэтому давайте.
Первым делом для того, чтобы объяснить как настраивать шахт машину на чарджера возьмем машину на турбине для этого нам подойдет, допустим, то же самое nsx гоним ее на дина-стенд и, ребята, сразу объясняю, в принципе я всем так говорю, но в этом видео повторю еще раз, а по факту, настройка самой коробки передач на charger и на турбину по факту, не различается, то есть настраивать все нужно точно так же для тех, кто совсем не знает как объясню чуть позже.
Итак, у нас есть машина на турбине давайте сделаем замер этого автомобиля ну и мы видим то что тест моменты у нас по факту, актуальный и отсюда смотрим, ребята, как же нам нужно здесь.
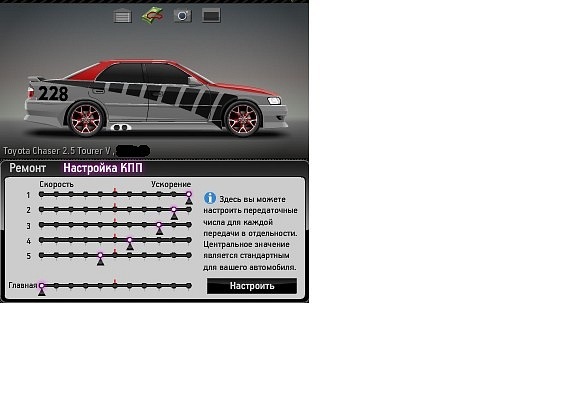
Вот самое главное настройки по факту это выставит лампочки, потому что.
Потом по лампочка мы сможем спокойно настраивать свой автомобиль.
Итак, что самое важное.
Первым делом, ребята, мы выставляем вот этот зеленую лампочку это у нас лаунч контроль есть у нас, конечно, есть, а если его нет, то зеленую лампочку выставлять необязательно, но если есть выставляем в зеленую лампочку, а куда вы и выставляем мы увидим желтую зону это наш момент и, естественно, зеленую лампочку мы выставляем на верхушку желтой зоны, но, как правило, мы берем ее чуть-чуть совсем, а вот сюда, то есть где-то вот так следующее это красные и желтые лампочки, в принципе красную мы пока не трогаем.
Первым делом смотрим на желтую, а желтую лампочку, ребята, нам нужно выставить туда где у нас момент разрастаться самое начало возрастном, то роста момента нас начинается вот здесь, а здесь прикидываем примерно некоторых точках лампочка выставляется сюда на некоторых, допустим, сюда некоторых еще еще дальше и так далее, а нам нужно прикинуть примерно, где нам хочется, чтобы наша стрелка оказывалось после переключения передач и смотрим, то есть примерно в нашей ситуации, но, наверное, самый оптимальный вариант моей ситуации будет ее поставить вот здесь и вот отсюда уже смотрим, то есть мы видим у нас вот здесь вот момент у нас вот здесь пересечение с желтой зоной, и соответственно, примерно в ту же самую точку нам и нужно поставить красную лампочку следовательно смотрим ведем по вот этой полоски зрительно глазами и видим то что у нас момент сдувается вот здесь следовательно сюда ставим красные, и после чего уже на стрим автомобиль на трассе на трассе когда мы делаем тестовый заезд у нас появляется определенная графа сейчас я стартанул и покажу его, то есть вот у нас, ребята, появился график, на котором есть отметки синяя желтая зеленая и красная и следовательно нам нужно сделать и настроить коробку, таким образом, чтобы перед при переключении в самом в конце зеленой зоны, а у нас откидывал, а стрелку до самого начала желтой зоны, то есть чтобы у нас стрелка не заходила на красную, но и при этом нет летала на синюю объясняю на некоторых автомобилях бывает какое-то что нужно, чтобы одна передача, допустим, отлетела на синюю зону, либо же бывает такой то что какую-то передачу нужно загнать красную зону, а бывает такой то что переплете перепись при переключении извиняюсь нужно, чтобы отлетала стрелка не до желтой зоны, а до зеленой, допустим, где-то до середины это бывает, но у нас есть инструкция не по настройке коробки передач инструкция по настройке коробки передач есть у меня на канале у нас здесь инструкция как настраиваться на чат люди следовательно мы поняли то что коробка нам нужно настраивать так, чтобы перри переключение передач и в самом в конце зеленой зоны стрелку нас отлетала самое начало желтой зоны, и при, ребята, мы берем точку над charger здесь charger у нас совсем слабенький это, естественно, skylight для турнира на 500 сил и charger у нас здесь, в принципе не мощный загоняем ее и на стенд, и что мы видимся джером charger у нас начинает раздуваться вот здесь и падать он начинает примерно где-то вот-вот в этом вот районе, а если у вас, ребята, будет более мощная тачка начали, как правило, допустим на тот же айпери там вообще вот идет, допустим, вот так вот момент вот так вот резко пик прямо треугольный прямо их такой углов, а, и после чего идет спад момента мы всегда выставляемся на самую высокую точку здесь, опять-таки, выставлять launch CTRL зеленую лампочку на самую высокую точку, после чего желтую лампочку, естественно, начала раздува и красную, естественно, на конец раздуло, а то есть мы смотрим у нас примерно вот, опять-таки, желтая лампочка у нас стоит вот здесь вот отсюда пример начала раздор раздува введем глазами приблизительно и понимаю то что красно нам нужно поставить примерно как-то вот так, чтобы они были на одном уровне, и соответственно, мы стартанули у нас стрелка прилетела в красную зону вот сюда вот мы переключились на стрелка об отлетела сюда отсюда опять идет идет идет идет плавно нарастает здесь опять вот переключились у нас опять стрелка до желтой зоны и таким образом, ребята, настраиваем себе коробку, на соответственно, charger и я надеюсь, что я ответил на ваш вопрос, как вы видите, все очень просто, то есть нам не начать жили, как правило, не нужно долбить в отсечку, потому что в отсечки, как вы можете видеть вообще нет моменты никакого, причем это вообще на всех читеров, то есть если вы приближаетесь к течка у вас момента совершенно нет, то есть можно до другой charged поставить, а момент будет идти вот так и плавно плавно, и здесь резкого так заканчиваться, но смысл тот же самый то что в отсечки у чарджера момента нет у чарджера куда больше моментов в самом в начале хороший момент середине и под конец он падает, но я думаю, что.
Самое главное я вам объясню то что вот настраивать нужно вот таком вот масштабе все, то есть нужно взять тот самый момент когда момент тот самый момент когда момент растет вверх, и после чего выстави туда желтую лампочку и взять момент когда момент идет вниз и выставить красную лампочку примерно так, чтобы она была на уровне желтой по графику, то есть, допустим, здесь у нас, а вот сколько у нас здесь деление раз полоска 2 3 4 пяти вот пять с половиной даже пять и три где-то вот опять 03 до, скажем, так, и соответственно, примерно так же он должна стоять и красная, то есть примерно на 50 3 от низа.
Что же, ребята, я надеюсь, что я ответил на ваши вопросы и, конечно же, есть вам помогло или понравилось это видео обязательно ставьте лайки подписывайтесь на канал и нажимайте на колокольчик, чтобы не пропустить новые ролики, а с вами был Олега всем огромное спасибо за то что смотрели этот видео всем огромной огромной удачи и всем пока.
Комментарии
Ошибки настройки роуминга | edo.
 ru
ru
В некоторых случаях при настройке роуминга в разделе «Приглашения» вы можете увидеть, что статус настройки сменился на «Ошибка».
Кликнув по такой компании, вы можете увидеть подробную информацию по ошибке.
Ниже мы собрали самые частые ошибки и рекомендации к ним.
|
Оператор ЭДО
|
Текст ошибки
|
Описание
|
Что делать
|
|
Такском
|
Error Code: ‘1001’; Description: ‘Получатель не зарегистрирован в системе’; Details: ‘Получатель: идентификатор_ЭДО‘
|
Или данная компания не работает в Такском или при отправке приглашения некорректно были указаны данные.
|
Обратитесь в техническую поддержку [email protected], указав свой ИНН-КПП, ИНН-КПП контрагента и оператора ЭДО Диадок.
|
|
Диадок (Контур)
|
Manual request from the operator is required
|
С данным клиентом Диадока возможна только ручная настройка роуминга
|
Отправьте скан письма о выборе ЭДО.Поток с подписью и печатью (скачать шаблон письма) на почту [email protected], указав в теме письма «Настройка роуминга с Диадоком».
|
|
Recipient allows to receive messages only from counteragents
|
Не завершен процесс ручной настройки роуминга.
|
Уточните у своего контрагента ИНН, КПП и идентификатор ЭДО и повторно направьте ему приглашение. Как это сделать читайте в Настройка роуминга с клиентом Такскома.
| |
|
СБИС (Тензор)
|
ИНН (КПП) получателя в приглашении отличается от ИНН в online.
|
При отправке приглашения в роуминг был некорректно указан ИНН, КПП или идентификатор ЭДО компании.
|
Уточните у своего контрагента ИНН, КПП и идентификатор ЭДО и повторно направьте ему приглашение. Как это сделать читайте в Настройка роуминга с клиентом СБИСа (Тензор).
|
|
Не удалось найти получателя с идентификатором идентификатор_ЭДО
| |||
|
Ошибка при обработке сообщения с идентификатором идентификатор_ЭДО: Получатель с идентификатором идентификатор_ЭДО не найден в online.sbis.ru
| |||
|
Ошибка обработки входящего сообщения с идентификатором идентификатор_сообщения (Отправитель приглашения c ИНН инн_клиента и КПП кпп_клиента уже привязан к идентификатору идентификатор_ЭДО в online.
|
Данная ошибка возникает, если до перехода в ЭДО.Поток вы пользовались другим оператором ЭДО.
|
1. Отправьте скан Письма о переходе на ЭДО.Поток (скачать шаблон письма) на почту [email protected], указав в теме письма «Переход с СБИС в ЭДО.Поток».
2. Или напишите в СБИС с просьбой удалить ваш кабинет в их системе.
После разовой настройки перенаправьте приглашение своему контрагенту в СБИС.
|

 sbis.ru
sbis.ru sbis.ru; Отправитель приглашения c ИНН инн_клиента и КПП кпп_клиента привязан к идентификатору идентификатор_ЭДО в online.sbis.ru)
sbis.ru; Отправитель приглашения c ИНН инн_клиента и КПП кпп_клиента привязан к идентификатору идентификатор_ЭДО в online.sbis.ru)
Не нашли ответ?
Задайте свой вопрос, воспользовавшись нашей формой
Хотите знать больше?
Перезвоним вам в течение 5 минут
и расскажем всё!
Спасибо!
Ожидайте звонка
Ошибка!
Попробуйте повторить запрос позже. ..
..
PostgreSQL: Документация: 15: 30.5. Конфигурация WAL
Существует несколько параметров конфигурации, связанных с WAL, которые влияют на производительность базы данных. В этом разделе объясняется их использование. Обратитесь к Главе 20 за общей информацией о настройке параметров конфигурации сервера.
Контрольные точки — это точки в последовательности транзакций, в которых гарантируется, что файлы данных кучи и индекса были обновлены всей информацией, записанной до этой контрольной точки. Во время контрольной точки все грязные страницы данных сбрасываются на диск, а в файл журнала записывается специальная запись контрольной точки. (Записи изменений ранее были сброшены в файлы WAL.) В случае сбоя процедура восстановления после сбоя просматривает последнюю запись контрольной точки, чтобы определить точку в журнале (известную как запись повтора), с которой она должна начать Операция ПОВТОР. Любые изменения, внесенные в файлы данных до этого момента, гарантированно будут уже на диске. Следовательно, после контрольной точки сегменты журнала, предшествующие сегменту, содержащему повторную запись, больше не нужны и могут быть переработаны или удалены. (При выполнении архивации WAL сегменты журнала должны быть заархивированы перед повторным использованием или удалением.)
Следовательно, после контрольной точки сегменты журнала, предшествующие сегменту, содержащему повторную запись, больше не нужны и могут быть переработаны или удалены. (При выполнении архивации WAL сегменты журнала должны быть заархивированы перед повторным использованием или удалением.)
Требование контрольной точки сброса всех грязных страниц данных на диск может вызвать значительную нагрузку ввода-вывода. По этой причине активность контрольной точки регулируется таким образом, что ввод-вывод начинается при запуске контрольной точки и завершается до того, как должна начаться следующая контрольная точка; это сводит к минимуму снижение производительности во время контрольных точек.
Серверный процесс контрольной точки периодически автоматически выполняет контрольную точку. Контрольная точка запускается каждые секунды checkpoint_timeout или если max_wal_size вот-вот будет превышен, в зависимости от того, что наступит раньше. Настройки по умолчанию — 5 минут и 1 ГБ соответственно. Если после предыдущей контрольной точки не было записано ни одного WAL, новые контрольные точки будут пропущены, даже если
Если после предыдущей контрольной точки не было записано ни одного WAL, новые контрольные точки будут пропущены, даже если checkpoint_timeout прошло. (Если используется архивация WAL и вы хотите установить более низкий предел частоты архивирования файлов, чтобы ограничить возможную потерю данных, вам следует настроить параметр archive_timeout, а не параметры контрольной точки.) Также можно принудительно установить контрольную точку. с помощью команды SQL CHECKPOINT .
Уменьшение checkpoint_timeout и/или max_wal_size приводит к более частому появлению контрольных точек. Это позволяет быстрее восстановиться после сбоя, поскольку потребуется переделывать меньше работы. Однако необходимо сбалансировать это с увеличением затрат на более частую очистку грязных страниц данных. Если установлено значение full_page_writes (по умолчанию), необходимо учитывать еще один фактор. Чтобы обеспечить согласованность страниц данных, первое изменение страницы данных после каждой контрольной точки приводит к регистрации всего содержимого страницы. В этом случае меньший интервал между контрольными точками увеличивает объем вывода в журнал WAL, что частично сводит на нет цель использования меньшего интервала и в любом случае приводит к большему дисковому вводу-выводу.
В этом случае меньший интервал между контрольными точками увеличивает объем вывода в журнал WAL, что частично сводит на нет цель использования меньшего интервала и в любом случае приводит к большему дисковому вводу-выводу.
Контрольные точки довольно затратны, во-первых, потому что они требуют записи всех грязных в данный момент буферов, а во-вторых, потому что они приводят к дополнительному последующему трафику WAL, как обсуждалось выше. Поэтому разумно установить достаточно высокие параметры контрольных точек, чтобы контрольные точки не случались слишком часто. В качестве простой проверки работоспособности ваших параметров контрольных точек вы можете установить параметр checkpoint_warning. Если контрольные точки расположены ближе друг к другу, чем checkpoint_warning секунд, в журнал сервера будет выведено сообщение с рекомендацией увеличить max_wal_size . Периодическое появление такого сообщения не является поводом для беспокойства, но если оно появляется часто, то следует увеличить параметры контроля КПП. Массовые операции, такие как большие передачи
Массовые операции, такие как большие передачи COPY , могут вызвать появление ряда таких предупреждений, если вы не установили достаточно большое значение max_wal_size .
Чтобы избежать переполнения системы ввода-вывода массой операций записи страниц, запись грязных буферов во время контрольной точки распределяется на определенный период времени. Этот период контролируется параметром checkpoint_completion_target, который задается как часть интервала между контрольными точками (настраивается с помощью checkpoint_timeout ). Скорость ввода-вывода настраивается таким образом, чтобы контрольная точка завершалась, когда истечет заданная доля из checkpoint_timeout секунд или до того, как будет превышено max_wal_size , в зависимости от того, что наступит раньше. При значении по умолчанию 0,9 можно ожидать, что PostgreSQL завершит каждую контрольную точку немного раньше следующей запланированной контрольной точки (приблизительно за 90% продолжительности последней контрольной точки). Это максимально распределяет ввод-вывод, чтобы нагрузка ввода-вывода контрольной точки была постоянной на протяжении всего интервала контрольной точки. Недостаток этого заключается в том, что продление контрольных точек влияет на время восстановления, поскольку необходимо будет хранить больше сегментов WAL для возможного использования при восстановлении. Пользователь, обеспокоенный количеством времени, необходимым для восстановления, может пожелать уменьшить
Это максимально распределяет ввод-вывод, чтобы нагрузка ввода-вывода контрольной точки была постоянной на протяжении всего интервала контрольной точки. Недостаток этого заключается в том, что продление контрольных точек влияет на время восстановления, поскольку необходимо будет хранить больше сегментов WAL для возможного использования при восстановлении. Пользователь, обеспокоенный количеством времени, необходимым для восстановления, может пожелать уменьшить checkpoint_timeout , чтобы контрольные точки возникали чаще, но по-прежнему распределяли ввод-вывод по интервалу контрольных точек. В качестве альтернативы checkpoint_completion_target можно уменьшить, но это приведет к более интенсивному вводу-выводу (во время контрольной точки) и времени меньшего ввода-вывода (после завершения контрольной точки, но до следующей запланированной контрольной точки), и поэтому не рекомендуется . Хотя для checkpoint_completion_target может быть установлено значение 1,0, обычно рекомендуется устанавливать значение не выше 0,9.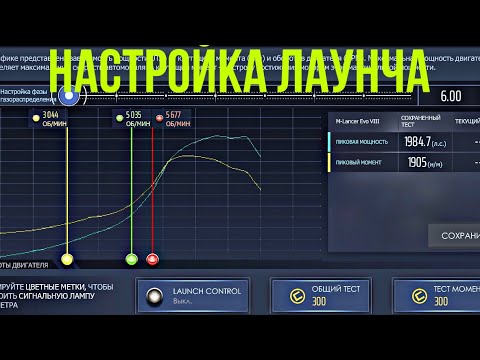 (по умолчанию), поскольку контрольные точки включают в себя некоторые другие действия, помимо записи грязных буферов. Значение 1.0, скорее всего, приведет к тому, что контрольные точки не будут завершены вовремя, что приведет к потере производительности из-за неожиданного изменения количества необходимых сегментов WAL.
(по умолчанию), поскольку контрольные точки включают в себя некоторые другие действия, помимо записи грязных буферов. Значение 1.0, скорее всего, приведет к тому, что контрольные точки не будут завершены вовремя, что приведет к потере производительности из-за неожиданного изменения количества необходимых сегментов WAL.
На платформах Linux и POSIX checkpoint_flush_after позволяет заставить ОС сбрасывать страницы, записанные контрольной точкой, на диск после заданного количества байтов. В противном случае эти страницы могут храниться в кэше страниц ОС, вызывая зависание при fsync выдается в конце контрольной точки. Этот параметр часто помогает уменьшить задержку транзакций, но также может негативно сказаться на производительности; особенно для рабочих нагрузок, которые больше, чем shared_buffers, но меньше, чем кеш страниц ОС.
Количество файлов сегментов WAL в каталоге pg_wal зависит от min_wal_size , max_wal_size и объема WAL, сгенерированного в предыдущих циклах контрольных точек. Когда старые файлы сегментов журнала больше не нужны, они удаляются или перерабатываются (то есть переименовываются, чтобы стать будущими сегментами в пронумерованной последовательности). Если из-за кратковременного пика скорости вывода бревна
Когда старые файлы сегментов журнала больше не нужны, они удаляются или перерабатываются (то есть переименовываются, чтобы стать будущими сегментами в пронумерованной последовательности). Если из-за кратковременного пика скорости вывода бревна max_wal_size превышен, ненужные файлы сегментов будут удалены до тех пор, пока система не вернется к этому пределу. Ниже этого предела система перерабатывает достаточно файлов WAL, чтобы покрыть расчетную потребность до следующей контрольной точки, а остальные удаляет. Оценка основана на скользящем среднем количестве файлов WAL, использованных в предыдущих циклах контрольных точек. Скользящее среднее немедленно увеличивается, если фактическое использование превышает оценку, поэтому оно в некоторой степени учитывает пиковое использование, а не среднее использование. min_wal_size устанавливает минимум количества файлов WAL, перерабатываемых для будущего использования; такое большое количество WAL всегда перерабатывается для использования в будущем, даже если система простаивает, а оценка использования WAL предполагает, что требуется небольшое количество WAL.
Независимо от max_wal_size самые последние wal_keep_size мегабайты файлов WAL плюс один дополнительный файл WAL сохраняются все время. Кроме того, если используется архивация WAL, старые сегменты не могут быть удалены или переработаны до тех пор, пока они не будут заархивированы. Если архивирование WAL не поспевает за темпами создания WAL или если archive_command или archive_library повторяется сбой, старые файлы WAL будут накапливаться в pg_wal , пока ситуация не разрешится. Медленный или неисправный резервный сервер, использующий слот репликации, будет иметь тот же эффект (см. раздел 27.2.6).
В режиме восстановления из архива или в режиме ожидания сервер периодически выполняет точек перезапуска , которые аналогичны контрольным точкам при нормальной работе: сервер принудительно записывает все свое состояние на диск, обновляет pg_control , чтобы указать, что уже обработанные данные WAL не нужно снова сканировать, а затем повторно использует все старые файлы сегментов журнала в каталоге pg_wal . Точки перезапуска не могут выполняться чаще, чем контрольные точки на первичном сервере, поскольку точки перезапуска могут выполняться только в записях контрольных точек. Точка перезапуска запускается при достижении записи контрольной точки, если с момента последней точки перезапуска прошло не менее
Точки перезапуска не могут выполняться чаще, чем контрольные точки на первичном сервере, поскольку точки перезапуска могут выполняться только в записях контрольных точек. Точка перезапуска запускается при достижении записи контрольной точки, если с момента последней точки перезапуска прошло не менее checkpoint_timeout секунд или если размер WAL вот-вот превысит max_wal_size . Однако из-за ограничений на то, когда может быть выполнена точка перезапуска, max_wal_size часто превышается во время восстановления на величину до одного цикла контрольной точки WAL. ( max_wal_size в любом случае никогда не является жестким ограничением, поэтому вы всегда должны оставлять достаточно места, чтобы избежать нехватки места на диске.)
Существуют две часто используемые внутренние функции WAL: XLogInsertRecord и XLogFlush . XLogInsertRecord используется для помещения новой записи в буферы WAL в разделяемой памяти. Если нет места для новой записи,
Если нет места для новой записи, XLogInsertRecord придется записать (переместить в кеш ядра) несколько заполненных буферов WAL. Это нежелательно, так как XLogInsertRecord используется для каждой модификации нижнего уровня базы данных (например, вставки строки) в то время, когда на затрагиваемых страницах данных удерживается монопольная блокировка, поэтому операция должна выполняться как можно быстрее. Что еще хуже, запись буферов WAL также может привести к созданию нового сегмента журнала, что занимает еще больше времени. Обычно буферы WAL должны быть записаны и очищены Запрос XLogFlush , который выполняется, по большей части, во время фиксации транзакции, чтобы гарантировать, что записи транзакций будут сброшены в постоянное хранилище. В системах с большим количеством выходных данных журнала запросы XLogFlush могут выполняться недостаточно часто, чтобы предотвратить необходимость записи XLogInsertRecord . В таких системах следует увеличить количество буферов WAL, изменив параметр wal_buffers. Когда full_page_writes установлен и система очень занята, установка
Когда full_page_writes установлен и система очень занята, установка wal_buffers выше поможет сгладить время отклика в течение периода, непосредственно следующего за каждой контрольной точкой.
Параметр commit_delay определяет, сколько микросекунд процесс-лидер групповой фиксации будет бездействовать после получения блокировки в пределах XLogFlush , в то время как последователи групповой фиксации выстраиваются в очередь позади лидера. Эта задержка позволяет другим серверным процессам добавлять свои записи фиксации в буферы WAL, чтобы все они были очищены возможной операцией синхронизации лидера. Спящий режим не произойдет, если fsync не включен или если в активных транзакциях в настоящее время находится менее чем commit_siblings других сеансов; это позволяет избежать сна, когда маловероятно, что какой-либо другой сеанс будет зафиксирован в ближайшее время. Обратите внимание, что на некоторых платформах разрешение запроса на спящий режим составляет десять миллисекунд, так что любые ненулевые значение commit_delay от 1 до 10000 микросекунд будет иметь тот же эффект. Также обратите внимание, что на некоторых платформах спящие операции могут занимать немного больше времени, чем требуется параметром.
Также обратите внимание, что на некоторых платформах спящие операции могут занимать немного больше времени, чем требуется параметром.
Поскольку цель commit_delay состоит в том, чтобы позволить стоимости каждой операции очистки амортизироваться между одновременно совершаемыми транзакциями (возможно, за счет задержки транзакции), необходимо количественно оценить эту стоимость, прежде чем параметр можно будет выбрать разумно. Чем выше эта стоимость, тем эффективнее 9Ожидается, что 0011 commit_delay увеличит пропускную способность транзакций до определенного момента. Программу pg_test_fsync можно использовать для измерения среднего времени в микросекундах, которое занимает одна операция очистки WAL. Значение, составляющее половину среднего времени, которое, по сообщениям программы, требуется для очистки после одной операции записи 8 КБ, часто является наиболее эффективной настройкой для commit_delay , поэтому это значение рекомендуется использовать в качестве отправной точки при оптимизации для конкретной рабочей нагрузки. При настройке
При настройке commit_delay особенно полезен, когда журнал WAL хранится на вращающихся дисках с высокой задержкой, преимущества могут быть значительными даже на носителях с очень быстрым временем синхронизации, таких как твердотельные накопители или массивы RAID с кэшем записи с резервным питанием от батареи; но это обязательно должно быть проверено на репрезентативной рабочей нагрузке. В таких случаях следует использовать более высокие значения commit_siblings , тогда как меньшие значения commit_siblings часто полезны на носителях с более высокой задержкой. Обратите внимание, что вполне возможно, что установка 9Слишком большое значение 0011 commit_delay может увеличить задержку транзакций настолько, что пострадает общая пропускная способность транзакций.
Когда commit_delay установлен в ноль (по умолчанию), по-прежнему возможно возникновение формы групповой фиксации, но каждая группа будет состоять только из сеансов, достигших точки, когда им необходимо сбросить свои записи фиксации во время окно, в котором происходит предыдущая операция сброса (если она была). При большем количестве клиентов имеет тенденцию возникать «эффект трапа», так что влияние групповой фиксации становится значительным, даже когда
При большем количестве клиентов имеет тенденцию возникать «эффект трапа», так что влияние групповой фиксации становится значительным, даже когда commit_delay равно нулю, поэтому явное задание commit_delay помогает меньше. Установка commit_delay может помочь только в том случае, если (1) есть несколько одновременно совершаемых транзакций и (2) пропускная способность в некоторой степени ограничена скоростью фиксации; но с высокой задержкой вращения этот параметр может быть эффективным для увеличения пропускной способности транзакций всего с двумя клиентами (то есть, один фиксирующий клиент с одной родственной транзакцией).
Параметр wal_sync_method определяет, как PostgreSQL будет запрашивать у ядра принудительную запись обновлений WAL на диск. Все варианты должны быть одинаковыми по надежности, за исключением fsync_writethrough , что иногда может привести к принудительной очистке кэша диска, даже если другие параметры этого не делают. Тем не менее, какая из них будет самой быстрой, зависит от конкретной платформы. Вы можете протестировать скорость различных опций с помощью программы pg_test_fsync. Обратите внимание, что этот параметр не имеет значения, если
Тем не менее, какая из них будет самой быстрой, зависит от конкретной платформы. Вы можете протестировать скорость различных опций с помощью программы pg_test_fsync. Обратите внимание, что этот параметр не имеет значения, если fsync отключен.
Включение параметра конфигурации wal_debug (при условии, что PostgreSQL был скомпилирован с его поддержкой) приведет к тому, что каждый XLogInsertRecord и XLogFlush Вызов WAL регистрируется в журнале сервера. Этот вариант может быть заменен более общим механизмом в будущем.
Существуют две внутренние функции для записи данных WAL на диск: XLogWrite и issue_xlog_fsync . Когда track_wal_io_timing включен, общее количество времени XLogWrite записи и issue_xlog_fsync синхронизации данных WAL с диском считается как wal_write_time и wal_sync_time в pg_stat_wal соответственно. XLogWrite обычно вызывается XLogInsertRecord (когда нет места для новой записи в буферах WAL), XLogFlush и модулем записи WAL для записи буферов WAL на диск и вызова issue_xlog_fsync .
issue_xlog_fsync обычно вызывается XLogWrite для синхронизации файлов WAL с диском. Если wal_sync_method равно open_datasync или open_sync , операция записи в XLogWrite гарантирует синхронизацию записанных данных WAL на диск, а issue_xlog_fsync ничего не делает. Если wal_sync_method равно fdatasync , fsync или fsync_writethrough , операция записи перемещает буферы WAL в кэш ядра, а issue_xlog_fsync синхронизирует их с диском. Независимо от настройки track_wal_io_timing количество раз, когда XLogWrite записывает и issue_xlog_fsync синхронизирует данные WAL на диск, также считается равным 9.0011 wal_write и wal_sync в pg_stat_wal соответственно.
Параметр recovery_prefetch можно использовать для сокращения времени ожидания ввода-вывода во время восстановления, указав ядру инициировать чтение дисковых блоков, которые скоро потребуются, но в настоящее время не находятся в пуле буферов PostgreSQL. Параметры Maintenance_io_concurrency и wal_decode_buffer_size ограничивают параллелизм и расстояние предварительной выборки соответственно. По умолчанию установлено значение
Параметры Maintenance_io_concurrency и wal_decode_buffer_size ограничивают параллелизм и расстояние предварительной выборки соответственно. По умолчанию установлено значение try , что включает функцию в системах, где posix_fadvise доступен.
Контрольные точки базы данных (SQL Server) — SQL Server
- Статья
- 8 минут на чтение
Применимо к:
SQL Server (все поддерживаемые версии)
База данных SQL Azure
Контрольная точка создает известную хорошую точку, с которой ядро СУБД SQL Server может начать применять изменения, содержащиеся в журнале, во время восстановления после неожиданного завершения работы или сбоя.
Обзор
Из соображений производительности Компонент Database Engine изменяет страницы базы данных в памяти, в буферном кеше и не записывает эти страницы на диск после каждого изменения. Вместо этого компонент Database Engine периодически выдает контрольную точку для каждой базы данных. Контрольная точка записывает текущие измененные страницы в памяти (известные как грязных страниц ) и информацию журнала транзакций из памяти на диск, а также записывает информацию в журнал транзакций.
Вместо этого компонент Database Engine периодически выдает контрольную точку для каждой базы данных. Контрольная точка записывает текущие измененные страницы в памяти (известные как грязных страниц ) и информацию журнала транзакций из памяти на диск, а также записывает информацию в журнал транзакций.
Компонент Database Engine поддерживает несколько типов контрольных точек: автоматические, непрямые, ручные и внутренние. В следующей таблице приведены типы контрольных точек.
| Имя | Интерфейс Transact-SQL | Описание |
|---|---|---|
| Автоматический | EXEC sp_configure ‘интервал восстановления’, ‘ секунд ‘ | Выдается автоматически в фоновом режиме для соблюдения верхнего предела времени, предложенного параметром конфигурации сервера интервал восстановления . Автоматические контрольные точки выполняются до завершения. Автоматические контрольные точки регулируются в зависимости от количества незавершенных операций записи и от того, обнаруживает ли Компонент Database Engine увеличение задержки записи более 50 миллисекунд. Дополнительные сведения см. в разделе Настройка параметра конфигурации сервера с интервалом восстановления. |
| Непрямой | ALTER DATABASE… SET TARGET_RECOVERY_TIME = target_recovery_time {SECONDS | МИНУТЫ } | Выдается в фоновом режиме для соблюдения заданного пользователем целевого времени восстановления для данной базы данных. Начиная с SQL Server 2016 (13.x), значение по умолчанию — 1 минута. Значение по умолчанию — 0 для более старых версий, что указывает на то, что база данных будет использовать автоматические контрольные точки, частота которых зависит от настройки интервала восстановления экземпляра сервера. Дополнительные сведения см. в разделе Изменение целевого времени восстановления базы данных (SQL Server). |
| Руководство | КОНТРОЛЬНАЯ ТОЧКА [ checkpoint_duration ] | Выдается при выполнении команды Transact-SQL CHECKPOINT. Ручная контрольная точка возникает в текущей базе данных для вашего подключения. По умолчанию ручные контрольные точки выполняются до завершения. Дросселирование работает так же, как и для автоматических контрольных точек. Опционально, checkpoint_duration 9Параметр 0006 указывает запрошенное количество времени в секундах для завершения контрольной точки. Ручная контрольная точка возникает в текущей базе данных для вашего подключения. По умолчанию ручные контрольные точки выполняются до завершения. Дросселирование работает так же, как и для автоматических контрольных точек. Опционально, checkpoint_duration 9Параметр 0006 указывает запрошенное количество времени в секундах для завершения контрольной точки.Дополнительные сведения см. в разделе ПРОВЕРКА (Transact-SQL). |
| Внутренний | Нет | Выдается различными серверными операциями, такими как резервное копирование и создание моментальных снимков базы данных, чтобы гарантировать, что образы дисков соответствуют текущему состоянию журнала. |
Параметр расширенной настройки SQL Server -k позволяет администратору базы данных регулировать поведение ввода-вывода контрольной точки в зависимости от пропускной способности подсистемы ввода-вывода для некоторых типов контрольных точек. 9Параметр настройки 0011 -k применяется к автоматическим контрольным точкам и любым другим нерегулируемым ручным и внутренним контрольным точкам.
9Параметр настройки 0011 -k применяется к автоматическим контрольным точкам и любым другим нерегулируемым ручным и внутренним контрольным точкам.
Для автоматических, ручных и внутренних контрольных точек во время восстановления базы данных необходимо выполнить повтор транзакций только для изменений, сделанных после последней контрольной точки. Это сокращает время, необходимое для восстановления базы данных.
Важно
Длительные незафиксированные транзакции увеличивают время восстановления для всех типов контрольных точек.
Взаимодействие опций TARGET_RECOVERY_TIME и «интервал восстановления»
В следующей таблице приведены сведения о взаимодействии между параметром «интервал восстановления» sp_configure для всего сервера и параметром ALTER DATABASE ... TARGET_RECOVERY_TIME для конкретной базы данных.
| ЦЕЛЕВОЕ_ВРЕМЯ ВОССТАНОВЛЕНИЯ | ‘интервал восстановления’ | Тип используемого контрольно-пропускного пункта |
|---|---|---|
| 0 | 0 | автоматических контрольных точек, целевой интервал восстановления которых составляет 1 минуту. |
| 0 | > 0 | Автоматические контрольные точки, целевой интервал восстановления которых определяется пользовательской настройкой параметра sp_configure 'recovery interval' . |
| > 0 | Неприменимо | Косвенные контрольные точки, целевое время восстановления которых определяется параметром TARGET_RECOVERY_TIME, выраженным в секундах. |
Автоматические контрольные точки
Автоматическая контрольная точка возникает каждый раз, когда количество записей в журнале достигает числа, которое, по оценке компонента Database Engine, оно может обработать за время, указанное в параметре 9.0231 интервал восстановления параметр конфигурации сервера. Дополнительные сведения см. в разделе Настройка параметра конфигурации сервера с интервалом восстановления.
В каждой базе данных без определяемого пользователем целевого времени восстановления компонент Database Engine создает автоматические контрольные точки. Частота зависит от параметра расширенной конфигурации сервера recovery interval , который указывает максимальное время, которое данный экземпляр сервера должен использовать для восстановления базы данных во время перезапуска системы. Компонент Database Engine оценивает максимальное количество записей журнала, которые он может обработать в течение интервала восстановления. Когда база данных, использующая автоматические контрольные точки, достигает этого максимального количества записей журнала, Компонент Database Engine создает контрольную точку для базы данных.
Частота зависит от параметра расширенной конфигурации сервера recovery interval , который указывает максимальное время, которое данный экземпляр сервера должен использовать для восстановления базы данных во время перезапуска системы. Компонент Database Engine оценивает максимальное количество записей журнала, которые он может обработать в течение интервала восстановления. Когда база данных, использующая автоматические контрольные точки, достигает этого максимального количества записей журнала, Компонент Database Engine создает контрольную точку для базы данных.
Интервал времени между автоматическими контрольными точками может быть сильно переменным. База данных со значительной рабочей нагрузкой транзакций будет иметь более частые контрольные точки, чем база данных, используемая в основном для операций только для чтения. В простой модели восстановления автоматическая контрольная точка также ставится в очередь, если журнал заполняется на 70 процентов.
В рамках простой модели восстановления, если какой-либо фактор не задерживает усечение журнала, автоматическая контрольная точка усекает неиспользуемый раздел журнала транзакций. Напротив, в моделях полного восстановления и восстановления с неполным протоколированием после создания цепочки резервного копирования журнала автоматические контрольные точки не вызывают усечения журнала. Дополнительные сведения см. в разделе Журнал транзакций (SQL Server).
После сбоя системы время, необходимое для восстановления данной базы данных, в значительной степени зависит от объема случайных операций ввода-вывода, необходимых для повторного выполнения страниц, которые были грязными во время сбоя. Это означает, что параметр интервала восстановления ненадежен. Он не может определить точную продолжительность восстановления. Кроме того, когда выполняется автоматическая контрольная точка, общая активность ввода-вывода для данных значительно и непредсказуемо возрастает.
Влияние интервала восстановления на эффективность восстановления
Для системы оперативной обработки транзакций (OLTP), использующей короткие транзакции, интервал восстановления является основным фактором, определяющим время восстановления. Однако параметр интервала восстановления не влияет на время, необходимое для отмены длительной транзакции. Восстановление базы данных с длительно выполняющейся транзакцией может занять намного больше времени, чем указано в параметре интервала восстановления .
Однако параметр интервала восстановления не влияет на время, необходимое для отмены длительной транзакции. Восстановление базы данных с длительно выполняющейся транзакцией может занять намного больше времени, чем указано в параметре интервала восстановления .
Например, если длительной транзакции потребовалось два часа для выполнения обновлений, прежде чем экземпляр сервера был отключен, фактическое восстановление займет значительно больше времени, чем интервал восстановления значение для восстановления длинной транзакции. Дополнительные сведения о влиянии длительной транзакции на время восстановления см. в разделе Журнал транзакций (SQL Server). Дополнительные сведения о процессе восстановления см. в разделе Обзор восстановления и восстановления (SQL Server).
Как правило, значения по умолчанию обеспечивают оптимальную производительность восстановления. Однако изменение интервала восстановления может улучшить производительность в следующих случаях:
Если вы решите увеличить интервал восстановления , мы рекомендуем увеличивать его постепенно небольшими приращениями и оценивать влияние каждого приращения на производительность восстановления. Этот подход важен, потому что по мере увеличения параметра интервала восстановления восстановление базы данных занимает во много раз больше времени. Например, если вы измените интервал восстановления на 10 минут, восстановление займет примерно в 10 раз больше времени, чем если интервал восстановления установлен на 1 минуту.
Этот подход важен, потому что по мере увеличения параметра интервала восстановления восстановление базы данных занимает во много раз больше времени. Например, если вы измените интервал восстановления на 10 минут, восстановление займет примерно в 10 раз больше времени, чем если интервал восстановления установлен на 1 минуту.
Непрямые контрольные точки
Косвенные контрольные точки, представленные в SQL Server 2012 (11.x), представляют собой настраиваемую альтернативу автоматическим контрольным точкам на уровне базы данных. Это можно настроить, указав параметр конфигурации базы данных target recovery time . Дополнительные сведения см. в разделе Изменение целевого времени восстановления базы данных (SQL Server).
В случае сбоя системы непрямые контрольные точки обеспечивают потенциально более быстрое и предсказуемое время восстановления, чем автоматические контрольные точки.
Косвенные контрольные точки имеют следующие преимущества:
Косвенные контрольные точки гарантируют, что количество грязных страниц ниже определенного порога, поэтому восстановление базы данных завершается в течение целевого времени восстановления.

Параметр конфигурации интервал восстановления использует количество транзакций для определения времени восстановления, в отличие от косвенных контрольных точек , которые используют количество грязных страниц. Когда непрямые контрольные точки включены для базы данных, получающей большое количество операций DML, фоновый модуль записи может начать агрессивно сбрасывать грязные буферы на диск, чтобы гарантировать, что время, необходимое для выполнения восстановления, находится в пределах целевого времени восстановления, установленного для базы данных. Это может привести к дополнительной активности ввода-вывода в некоторых системах, что может стать узким местом в производительности, если дисковая подсистема работает выше порога ввода-вывода или приближается к нему.
Непрямые контрольные точки позволяют надежно контролировать время восстановления базы данных, учитывая стоимость произвольного ввода-вывода во время REDO. Это позволяет экземпляру сервера оставаться в пределах верхнего предела времени восстановления для данной базы данных (за исключением случаев, когда длительная транзакция приводит к чрезмерному времени UNDO).
Непрямые контрольные точки снижают пиковые нагрузки ввода-вывода, связанные с контрольными точками, за счет постоянной записи грязных страниц на диск в фоновом режиме.

Однако оперативная транзакционная рабочая нагрузка на базу данных, настроенную для непрямых контрольных точек, может привести к снижению производительности. Это связано с тем, что фоновый модуль записи, используемый косвенной контрольной точкой, иногда увеличивает общую нагрузку записи для экземпляра сервера.
Важно
Непрямая контрольная точка — это поведение по умолчанию для новых баз данных, созданных в SQL Server 2016 (13.x), включая базы данных model и tempdb .
Базы данных, которые были обновлены на месте или восстановлены из предыдущей версии SQL Server, будут использовать предыдущее поведение автоматической контрольной точки, если явно не изменено для использования непрямой контрольной точки.
Улучшенная масштабируемость непрямых контрольных точек
В версиях, предшествующих SQL Server 2019 (15. x), вы могли столкнуться с ошибками планировщика, не приводящими к урожаю, когда имеется база данных, создающая большое количество грязных страниц, например
x), вы могли столкнуться с ошибками планировщика, не приводящими к урожаю, когда имеется база данных, создающая большое количество грязных страниц, например tempdb . В SQL Server 2019 (15.x) реализована улучшенная масштабируемость для непрямых контрольных точек, что должно помочь избежать этих ошибок в базах данных с большой рабочей нагрузкой.
Внутренние контрольные точки
Внутренние контрольные точки генерируются различными компонентами сервера, чтобы гарантировать, что образы дисков соответствуют текущему состоянию журнала. Внутренние контрольные точки генерируются в ответ на следующие события:
Файлы базы данных были добавлены или удалены с помощью команды ALTER DATABASE.
Создана резервная копия базы данных.
Моментальный снимок базы данных создается явно или внутренне для DBCC CHECKDB.
Выполняется действие, требующее завершения работы базы данных. Например, AUTO_CLOSE включен, и последнее пользовательское соединение с базой данных закрыто, или внесены изменения в параметры базы данных, требующие перезапуска базы данных.
