Содержание
Для чего нужен режим L на автомате и прочие ограничивающие режимы (2 или 2L, 3 или D3)
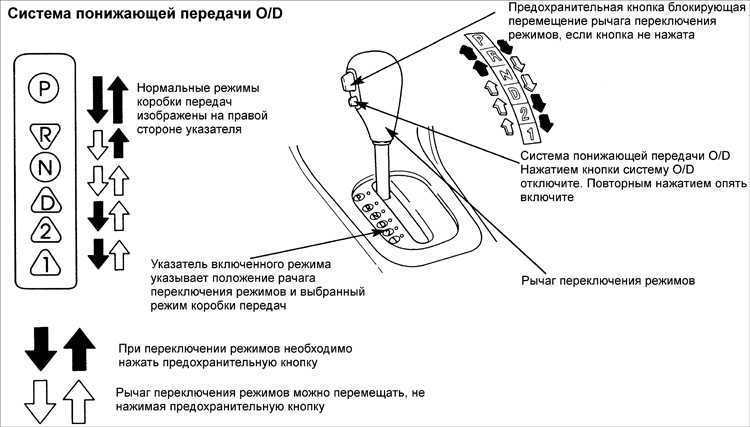
Во многих автоматах (преимущественно у агрегатов прошлых поколений) имеется так называемый режим пониженной передачи, обычно обозначаемый буквой L (Low), иногда цифрой 1 и еще реже буквой B (Bottom). Этот режим заставляет работать автомат на фиксированной первой передаче, чтобы коробка не переключалась вверх при увеличении оборотов двигателя.
Сразу отметим, что при достижении слишком высоких оборотов (обычно доходя до красной отсечки на тахометре) в режиме L коробка в итоге все равно перейдет на вторую передачу, дабы уберечь свой механизм от интенсивного износа.
Пониженная (первая) передача у автомата используется для преодоления крутых подъемов, либо чтобы заехать даже на относительно небольшую горку на груженном автомобиле, а также чтобы автомобиль не ускорялся на затяжных спусках, и не перегревать при этом тормоза, используя так называемое торможение двигателем.
Также данный режим позволяет избежать излишней пробуксовки на скользкой поверхности или во время преодоления сложных грязевых или заснеженных участков. Ведь при буксовании автомат думает, что автомобиль разгоняется, и в обычном режиме D (Drive) начинает переключать передачи на повышенные, снижая тем самым передаваемое тяговое усилие на колеса и, как следствие, понижая шансы преодолеть сложный непролазный участок дороги.
Включать режим L нужно стараться как можно реже – лишь в самых крайних случаях, описанных выше, поскольку автомат не особо любит работать на низкой передаче при высоких оборотах. Переводить рычаг в положение L можно в движении (также как и отключать данный режим), но рекомендуется делать это на скорости не более 25 км/ч.
Помимо фиксированной первой передачи, у автомата могут быть режимы 2 или L2 (2L), 3 или D3 (3D) и даже 4 или D4 (4D), заставляющие работать коробку в диапазонах соответственно не выше второй, третьей и четвертой передачи. Используются данные режимы в тех ситуациях, когда нужно задействовать торможение двигателем ради большей стабильности и устойчивости, например на скользкой дороге или горных серпантинах. Также, например, режим 3 или D3 можно задействовать при езде на относительно невысокой скорости, дабы не мучить коробку частыми переключениями с третьей на четвертую передачу.
Используются данные режимы в тех ситуациях, когда нужно задействовать торможение двигателем ради большей стабильности и устойчивости, например на скользкой дороге или горных серпантинах. Также, например, режим 3 или D3 можно задействовать при езде на относительно невысокой скорости, дабы не мучить коробку частыми переключениями с третьей на четвертую передачу.
В настоящее время на новых автомобилях очень редко можно встретить автоматы с отдельными режимами, ограничивающими работу коробки на низких передачах, но в качестве альтернативы у современных АКПП имеется режим ручного переключения M (Manual) (иногда обозначается просто + и —), позволяющий использовать любую фиксированную передачу, в частности для всех вышеописанных нужд.
 youtube.com/embed/1taLViaH0MA» title=»YouTube video player» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»>
youtube.com/embed/1taLViaH0MA» title=»YouTube video player» frameborder=»0″ allow=»accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture» allowfullscreen=»»> Для чего на автоматических коробках имеются понижающие передачи L?
На автоматических коробках передач первого поколения, которые еще не имели функции ручного управления скоростями, использовалась специальная конструкция с понижающими передачами. Многие водители попросту не понимают, для чего на автомате необходимы понижающие передачи и как правильно использовать такую коробку передач. Разберем подробнее, для чего используются понижающие передачи на автомате.
Основное назначение понижающих передач
Конструкция автомата такова, что при включении понижающей передачи в автомате на привод автомобиля передаётся больший крутящий момент, что позволяет с легкостью форсировать глубокие лужи, размытые просёлочные дороги и другие сложные участки. Тогда как в обычном режиме автомата машине просто не будет хватать мощности и крутящего момента, чтобы выбраться из такой глубокой ямы или топкого участка.
Тогда как в обычном режиме автомата машине просто не будет хватать мощности и крутящего момента, чтобы выбраться из такой глубокой ямы или топкого участка.
На механической коробке передач водитель сам может регулировать мощность и крутящий момент, который передается на ведущие колеса. У многих внедорожников имеется также полноценная понижающая передача, которая позволяет уверенно себя чувствовать на бездорожье. До появления таких понижающих передач на автоматах использовать машины на разбитой дороге было крайне сложно. Однако сегодня владельцы таких автомобилей могут уверенно себя чувствовать на проселочных дорогах, будучи уверенными, что они не застрянут в первой же глубокой луже.
Особенности понижающих передач на автоматах
Изначально такие понижающие передачи на автоматических коробках были прерогативой полноценных внедорожников, владельцы которых часто выбирались на разбитые дороги. Однако в последующем такая конструкция совершенствовалась, что позволило оснастить понижающими передачами все без исключения автоматы.
При использовании автомобиля с такой коробкой передач её владельцу необходимо помнить о том, что постоянное использование такого режима приводит к повышенной нагрузке на трансмиссию и перегреву автомата. Поэтому водителю не следует, как только он выбрался на загородную разбитую дорогу, включать понижающую передачу и двигаться всё время на ней. Её нужно активировать лишь в том случае, когда требуется преодолеть сложный участок дороги.
Если же пришлось длительное время держать включенной такую понижающую передачу, то, выбравшись с разбитой дороги, следует на 10-20 минут заглушить автомобиль, что позволит трансмиссионному маслу и всей автоматической коробке передач остыть, исключая критические неисправности у автомобиля. Если же пренебрегать такой рекомендацией, то, в конечном счете, потребуется выполнять замену блока управления коробкой или же проводить диагностику и замену железной части АКПП.
Такие трансмиссии автомат оснащаются даже не одним, а сразу двумя режимами понижающих передач.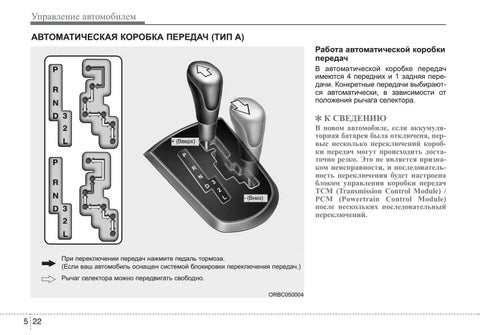 При переводе селектора в режим D3 коробка не будет переключаться на ступени выше третьей передачи. Тем самым уже с самого низа на ведущие колёса приходится значительный крутящий момент, позволяя выбираться из топкого грунта. На отдельных автомобилях также имеются специальные режимы «Камни», «Гололёд», «Грязь» и «Снег». Фактически, это те же самые понижающие передачи, причём ограничение может устанавливаться на третьей и даже второй ступени.
При переводе селектора в режим D3 коробка не будет переключаться на ступени выше третьей передачи. Тем самым уже с самого низа на ведущие колёса приходится значительный крутящий момент, позволяя выбираться из топкого грунта. На отдельных автомобилях также имеются специальные режимы «Камни», «Гололёд», «Грязь» и «Снег». Фактически, это те же самые понижающие передачи, причём ограничение может устанавливаться на третьей и даже второй ступени.
Современные коробки передач получили полностью электронное управление, они имеют функцию ручного переключения ступеней и спортивный режим, когда коробка максимально долго удерживает высокие обороты. Подобное позволило несколько повысить комфорт использования автомобиля на автомате, однако на разбитых дорогах возможности таких автомобилей в сравнении с машинами, у которых автомат имеет понижающую передачу, всё же ограничены.
Подведём итоги
В прошлом коробки передач автомат часто оснащались специальными понижающими передачами, что расширяло возможности таких машин на разбитых дорогах. Фактически, происходила блокировка коробки, которая не могла подниматься на четвёртую или третью передачу. Это позволяло обеспечить больший крутящий момент на ведущих колесах, а водитель мог выбраться из топкого грунта или разбитой раскисшей колеи. Нужно лишь помнить о том, что длительная активация таких понижающих передач приводит к перегреву трансмиссии, поэтому требуется охлаждать коробку и не активировать такие режимы на долго.
Фактически, происходила блокировка коробки, которая не могла подниматься на четвёртую или третью передачу. Это позволяло обеспечить больший крутящий момент на ведущих колесах, а водитель мог выбраться из топкого грунта или разбитой раскисшей колеи. Нужно лишь помнить о том, что длительная активация таких понижающих передач приводит к перегреву трансмиссии, поэтому требуется охлаждать коробку и не активировать такие режимы на долго.
12.07.2020
Что такое машинное обучение Blackbox — как оно работает?
Следуйте за нами!
ThumbsUp
[email protected]+44 20 3997 6090
© Авторское право SEON Technologies Ltd. – Правовая информация и безопасность
Что такое машинное обучение Blackbox?
В общих чертах машинное обучение «черный ящик» относится к моделям машинного обучения, которые дают вам результат или принимают решение, не объясняя и не показывая, как они это сделали. Используемые внутренние процессы и различные взвешенные факторы остаются неизвестными.
Другими словами, этой технологии не хватает прозрачности. Модель черного ящика означает, что ни один человек — даже программисты и администраторы машины или алгоритма — не знает и не понимает, как был достигнут результат.
Только сам алгоритм знает, как именно были приняты решения.
Что такое машинное обучение Blackbox для предотвращения мошенничества?
Машинное обучение Blackbox для предотвращения мошенничества дает вам оценку мошенничества, не сообщая и не показывая, как была достигнута эта оценка. Пользователь узнает только результат этих сложных вычислений.
Итак, данные входят, и результат — оценка риска — выходит, но мы не знаем, что происходит между ними. Поэтому мы также не можем корректировать или настраивать эти внутренние процессы.
В каком-то смысле это означает, что мы находимся во власти алгоритма, поскольку не знаем, что влияет на результирующую оценку риска.
Машинное обучение может ускорить обнаружение мошенничества.
Узнайте, как система машинного обучения «белый ящик» SEON предлагает мощные и прозрачные рекомендации по правилам, которые помогут вам вывести защиту от мошенничества на новый уровень.
Подробнее
Как работает машинное обучение Blackbox?
- В своей простейшей форме машинное обучение включает в себя ввод огромного количества примеров данных в алгоритм и предоставление ему возможности самообучаться.
- После этого «обучения» модель машинного обучения готова получать реальные данные, обрабатывать их и выдавать нам результат — обнаружение мошенничества, оценку риска.
- Все это время, по мере того, как он получает все больше и больше информации, он масштабирует свой алгоритм, методы и знания с помощью этих новых данных.
Но как именно он это делает? Какую роль играет каждый бит информации в процессе, который дал нам этот результат?
Система черного ящика не может нам сказать. Другими словами, точно так же, как мы не можем заглянуть внутрь ящика, окрашенного в черный цвет, мы также не знаем, как работает каждая модель машинного обучения «черный ящик».
Альтернативный способ рассмотреть это — посмотреть на особенности и разбивку того, как работает машинное обучение черного ящика в SEON, в нашей открытой документации, в качестве примера.
Почему важно машинное обучение Blackbox?
Несмотря на присущий ему недостаток прозрачности, машинное обучение методом «черного ящика» очень популярно и может быть полезным в определенных условиях. На самом деле, подавляющее большинство моделей машинного обучения, которые будут использоваться в 2021 году и далее, представляют собой «черные ящики».
Машинное обучение «черного ящика» использует такие технологии, как:
- большие данные
- сходство строк
- глубокое обучение
- нейронные сети
С помощью машинного обучения «черный ящик» мы можем ответить на вопрос «Какова оценка риска X ?» но мы никогда не сможем ответить на вопрос « Почему система считает, что это точная оценка риска для X? »
Если бы мы могли ответить на вопрос «почему», система была бы автоматически классифицирована как система машинного обучения белого ящика.
Как машинное обучение Blackbox помогает бороться с мошенничеством?
Как инструмент борьбы с мошенничеством, машинное обучение «черный ящик» может помочь нам выявить сложные связи и факторы.
- Он основан на сложных классификациях, основанных на вероятности, но в нем нет прозрачности, которую вы получаете с решением белого ящика.
- Это позволяет нам обрабатывать больше информации, чем это возможно, и делать это быстро.
- Лучше, чем вайтбокс, ловит новые, уникальные и изощренные попытки мошенничества.
Однако у него есть недостатков .
При обнаружении мошенничества использование платформы машинного обучения исключительно на основе черного ящика означает, что вы, как ее пользователь, не полностью осведомлены о ее внутренних махинациях, поэтому вы не можете знать, работает ли она для вас и ваших нужд. Вы также не сможете изменить параметры и деревья решений, которые он использует для принятия решений.
В зависимости от ваших требований считается выгодным выбирать решения с использованием белого ящика, где это возможно, или даже их комбинацию.
Почему Blackbox лучше Whitebox?
В предотвращении и обнаружении мошенничества машинное обучение «черный ящик» дает определенные преимущества:
- Скорость : система может обрабатывать огромные объемы данных и предоставлять результаты быстрее, чем люди, а также быстрее, чем система белого ящика.
- Использование больших данных : Большие наборы данных хорошо подходят для систем черного ящика.
- Работает без присмотра : Людям не нужно настраивать или одобрять внутреннюю работу системы и способы принятия решений.
- Может идентифицировать новые шаблоны : Модели «черного ящика» с большей вероятностью предсказывают и оттачивают новые уникальные или изощренные попытки мошенничества.
Тем не менее, лучший ответ заключается в том, что есть случаи, когда черный ящик лучше, и другие, где подход белого ящика идеален.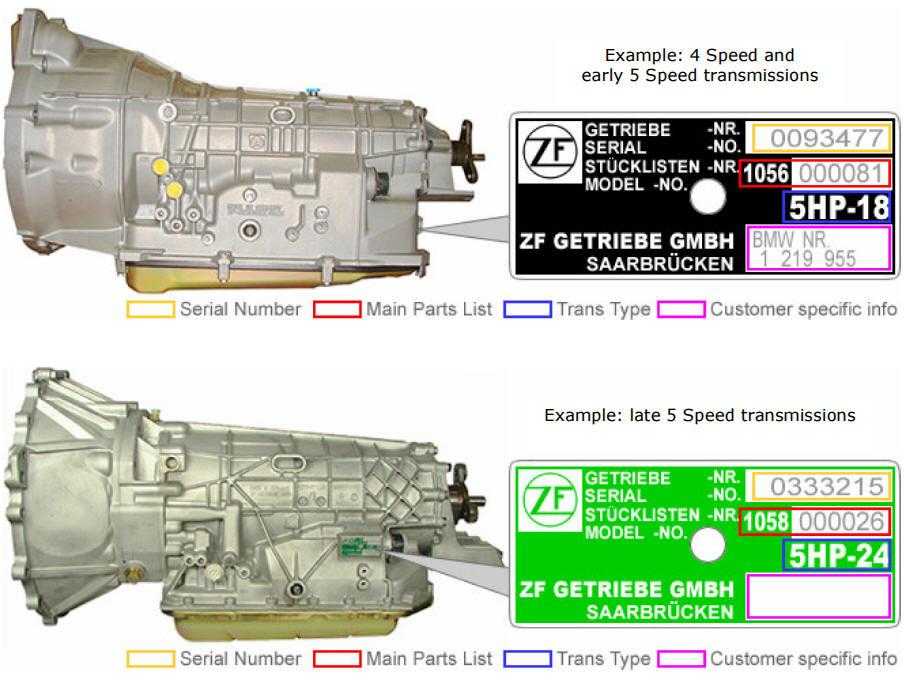
Есть ли преимущество в прозрачности (известности) алгоритмов и расчетов, или они приемлемы, если они непрозрачны, дают вам только результат оценки, не раскрывая, как именно он был получен?
Модель черного ящика означает, что вы можете видеть ввод и вывод, но не знаете, что происходит между ними. Проще говоря, черный ящик — это необъяснимое машинное обучение (в то время как белый ящик — это объяснимое машинное обучение).
Когда важна скорость, а точность второстепенна, может быть рекомендовано решение «черный ящик». С другой стороны, решения «белого ящика» Сделайте выбор в пользу качества (и точности), а не количества .
Конечно, любое машинное обучение позволяет нам сократить время, затрачиваемое на просмотр информации вручную, и у каждого метода есть свое применение.
Связанные термины
Машинное обучение Whitebox
Проверка вручную
Профилирование в социальных сетях
Статьи по теме
Обнаружение мошенничества с помощью машинного обучения и ИИ
Человек против машины
При выборе инструмента для предотвращения мошенничества
0005
Борьба с мошенничеством с помощью машинного обучения
Свяжитесь с нами для демонстрации
Не стесняйтесь обращаться к нам за демонстрацией!
Почему мы используем модели черного ящика в ИИ, когда нам это не нужно? Урок из конкурса по объяснимому ИИ · Выпуск 1.
 2, осень 2019 г.
2, осень 2019 г.
В 2018 году состоялось знаковое соревнование в области искусственного интеллекта (ИИ), а именно — конкурс объяснимого машинного обучения. Цель конкурса состояла в том, чтобы создать сложную модель черного ящика для набора данных и объяснить, как она работает. Одна команда не соблюдала правила. Вместо того, чтобы отправить в черный ящик, они создали полностью интерпретируемую модель. Это приводит к вопросу о том, похож ли реальный мир машинного обучения на задачу объяснимого машинного обучения, где модели черного ящика используются даже тогда, когда они не нужны. Мы обсуждаем мыслительные процессы этой команды во время соревнований и их последствия, которые выходят далеко за рамки самих соревнований.
Ключевые слова: интерпретируемость, объяснимость, машинное обучение, финансы.
. ), на которой будут подведены итоги «Объяснимого машинного обучения» — престижного конкурса, организованного совместно Google, Fair Isaac Corporation (FICO) и учеными из Беркли, Оксфорда, Империала, Калифорнийского университета в Ирвине и Массачусетского технологического института. Это был первый конкурс по науке о данных, который отражал необходимость осмысления результатов, рассчитанных с помощью моделей черного ящика, которые доминируют в процессе принятия решений на основе машинного обучения.
Это был первый конкурс по науке о данных, который отражал необходимость осмысления результатов, рассчитанных с помощью моделей черного ящика, которые доминируют в процессе принятия решений на основе машинного обучения.
За последние несколько лет достижения в области глубокого обучения для компьютерного зрения привели к широко распространенному убеждению, что самые точные модели для любой конкретной задачи науки о данных должны быть неинтерпретируемыми и сложными по своей сути. Это убеждение проистекает из исторического использования машинного обучения в обществе: его современные методы рождались и развивались для принятия решений с низкими ставками, таких как онлайн-реклама и веб-поиск, где индивидуальные решения не сильно влияют на жизнь людей.
В машинном обучении эти модели черного ящика создаются непосредственно из данных с помощью алгоритма, а это означает, что люди, даже те, кто их разрабатывает, не могут понять, как комбинируются переменные, чтобы делать прогнозы.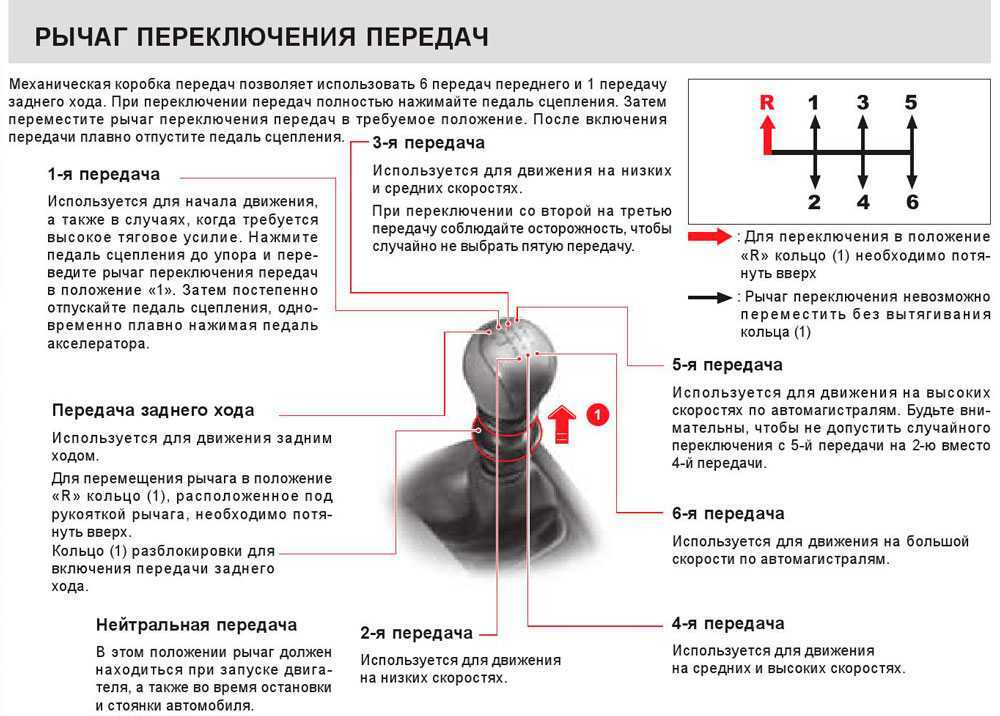 Даже если у вас есть список входных переменных, прогностические модели черного ящика могут быть такими сложными функциями переменных, что ни один человек не может понять, как переменные связаны друг с другом для получения окончательного прогноза.
Даже если у вас есть список входных переменных, прогностические модели черного ящика могут быть такими сложными функциями переменных, что ни один человек не может понять, как переменные связаны друг с другом для получения окончательного прогноза.
Интерпретируемые модели, которые представляют собой технически эквивалентную, но, возможно, более этичную альтернативу моделям черного ящика, отличаются тем, что они ограничены, чтобы обеспечить лучшее понимание того, как делаются прогнозы. В некоторых случаях можно очень четко определить, как переменные совместно связаны для формирования окончательного прогноза, когда, возможно, только несколько переменных объединяются в коротком логическом утверждении, или с помощью линейной модели, где переменные взвешиваются и складываются вместе. Иногда интерпретируемые модели состоят из более простых моделей, собранных вместе (разложимых), или на модель накладываются другие ограничения, чтобы добавить новый уровень понимания. Однако большинство моделей машинного обучения не имеют ограничений по интерпретируемости; они просто разработаны, чтобы быть точными предикторами в статическом наборе данных, которые могут или не могут отражать, как модель будет использоваться на практике.
Вера в то, что точность должна быть принесена в жертву интерпретируемости, ошибочна. Это позволило компаниям продвигать на рынок и продавать запатентованные или сложные модели черного ящика для принятия решений с высокими ставками, тогда как для тех же задач существуют очень простые интерпретируемые модели. Таким образом, это позволяет создателям моделей получать прибыль, не принимая во внимание вредные последствия для пострадавших лиц. Мало кто сомневается в этих моделях, потому что их разработчики утверждают, что модели должны быть сложными, чтобы быть точными. Вызов объяснимого машинного обучения 2018 года служит примером для рассмотрения компромиссов между предпочтением моделей черного ящика по сравнению с интерпретируемыми.
Перед объявлением победителей конкурса аудиторию, состоящую из влиятельных игроков в области финансов, робототехники и машинного обучения, попросили принять участие в мысленном эксперименте, в котором они болели раком и нуждались в операции по удалению опухоли. . На экране отображались два изображения. На одном изображении был изображен человек-хирург, который мог объяснить что угодно об операции, но имел 15-процентный шанс вызвать смерть во время операции. На другом изображении была показана роботизированная рука, которая могла выполнить операцию с вероятностью отказа всего 2%. Робот должен был имитировать подход «черный ящик» к искусственному интеллекту (ИИ). В этом сценарии требовалось полное доверие к роботу; роботу нельзя было задавать вопросы, и не было предоставлено никакого конкретного понимания того, как он пришел к своим решениям. Затем зрителей попросили поднять руку, чтобы проголосовать за того, за кого из двух они предпочли бы провести операцию по спасению жизни. Все, кроме одной руки, проголосовали за робота.
. На экране отображались два изображения. На одном изображении был изображен человек-хирург, который мог объяснить что угодно об операции, но имел 15-процентный шанс вызвать смерть во время операции. На другом изображении была показана роботизированная рука, которая могла выполнить операцию с вероятностью отказа всего 2%. Робот должен был имитировать подход «черный ящик» к искусственному интеллекту (ИИ). В этом сценарии требовалось полное доверие к роботу; роботу нельзя было задавать вопросы, и не было предоставлено никакого конкретного понимания того, как он пришел к своим решениям. Затем зрителей попросили поднять руку, чтобы проголосовать за того, за кого из двух они предпочли бы провести операцию по спасению жизни. Все, кроме одной руки, проголосовали за робота.
Хотя может показаться очевидным, что 2-процентная вероятность смертности лучше, чем 15-процентная вероятность смертности, такая формулировка ставок систем ИИ скрывает более фундаментальное и интересное соображение: Почему робот должен быть черным ящиком? ? Потеряет ли робот способность выполнять точную операцию, если он будет наделен способностью объясняться? Разве улучшение связи между роботом и пациентом или врачом не улучшит уход за пациентом, а не ухудшит его? Разве пациент не должен объяснить роботу, что у него нарушение свертываемости крови перед операцией?
Эта возможность, что робот не обязательно должен быть черным ящиком, не была представлена как вариант, и зрителям семинара был предоставлен только выбор между точным черным ящиком и неточным стеклянным ящиком. Зрителям не сообщили, как измерялась точность хирургических результатов (в какой популяции измерялись 2% и 15%?), а также о потенциальных недостатках в наборе данных, который использовался для обучения робота. Предполагая, что точность должна достигаться за счет интерпретируемости (способности понять, почему хирург делает то, что он делает), этот мысленный эксперимент не учитывал, что интерпретируемость не может повредить точности. Интерпретируемость может даже повысить точность, поскольку она позволяет понять, когда модель, в данном случае робота-хирурга, может быть неверной.
Зрителям не сообщили, как измерялась точность хирургических результатов (в какой популяции измерялись 2% и 15%?), а также о потенциальных недостатках в наборе данных, который использовался для обучения робота. Предполагая, что точность должна достигаться за счет интерпретируемости (способности понять, почему хирург делает то, что он делает), этот мысленный эксперимент не учитывал, что интерпретируемость не может повредить точности. Интерпретируемость может даже повысить точность, поскольку она позволяет понять, когда модель, в данном случае робота-хирурга, может быть неверной.
Если вас просят выбрать точную машину или понятного человека, это ложная дихотомия. Понимание этого как такового помогает нам диагностировать проблемы, возникшие в результате использования моделей черного ящика для принятия решений с высокими ставками во всем обществе. Эти проблемы существуют в финансах, а также в здравоохранении, уголовном правосудии и не только.
Приведем некоторые доказательства того, что это предположение (о том, что мы всегда должны жертвовать некоторой интерпретируемостью, чтобы получить наиболее точную модель) неверно. В системе уголовного правосудия неоднократно демонстрировалось (Angelino, Larus-Stone, Alabi, Seltzer, & Rudin, 2018; Tollenaar & van der Heijden, 2013; Zeng, Ustun, & Rudin, 2016), что сложные модели черного ящика для предсказания будущего ареста не более точны, чем очень простые модели предсказания, основанные на возрасте и криминальном прошлом. Например, интерпретируемая модель машинного обучения для прогнозирования повторного ареста, созданная в работе Angelino et al. (2018), рассматривает лишь несколько правил, касающихся чьего-либо возраста и криминального прошлого. Полная модель машинного обучения выглядит следующим образом: если человек совершил > 3 предыдущих преступления, или ему 18–20 лет и он мужчина, или 21–23 года и совершил два или три предыдущих преступления, он, по прогнозам, будет повторно арестован. в течение двух лет после их оценки, а в противном случае — нет. Хотя мы не обязательно выступаем за использование этой конкретной модели в условиях уголовного правосудия, этот набор правил так же точен, как и широко используемая (и запатентованная) модель черного ящика под названием COMPAS (профилирование управления исправительными преступниками для альтернативных санкций), которая используется в Broward.
В системе уголовного правосудия неоднократно демонстрировалось (Angelino, Larus-Stone, Alabi, Seltzer, & Rudin, 2018; Tollenaar & van der Heijden, 2013; Zeng, Ustun, & Rudin, 2016), что сложные модели черного ящика для предсказания будущего ареста не более точны, чем очень простые модели предсказания, основанные на возрасте и криминальном прошлом. Например, интерпретируемая модель машинного обучения для прогнозирования повторного ареста, созданная в работе Angelino et al. (2018), рассматривает лишь несколько правил, касающихся чьего-либо возраста и криминального прошлого. Полная модель машинного обучения выглядит следующим образом: если человек совершил > 3 предыдущих преступления, или ему 18–20 лет и он мужчина, или 21–23 года и совершил два или три предыдущих преступления, он, по прогнозам, будет повторно арестован. в течение двух лет после их оценки, а в противном случае — нет. Хотя мы не обязательно выступаем за использование этой конкретной модели в условиях уголовного правосудия, этот набор правил так же точен, как и широко используемая (и запатентованная) модель черного ящика под названием COMPAS (профилирование управления исправительными преступниками для альтернативных санкций), которая используется в Broward. округ, Флорида (Angelino et al., 2018).
округ, Флорида (Angelino et al., 2018).
Приведенная выше простая модель так же точна, как и многие другие современные методы машинного обучения (Angelino et al., 2018). Сходные результаты были получены в методах машинного обучения, примененных ко многим различным типам задач прогнозирования повторной фиксации в других наборах данных: интерпретируемые модели (которые в этих исследованиях были очень маленькими линейными моделями или логическими моделями) работали так же хорошо, как и более сложные (черный ящик). модели машинного обучения (Zeng et al., 2016). По-видимому, нет доказательств преимуществ использования моделей черного ящика для прогнозирования криминального риска. На самом деле могут быть недостатки в том, что эти черные ящики труднее устранять, доверять и использовать.
Точность моделей «черного ящика» в нескольких областях здравоохранения и во многих других приложениях машинного обучения с высокими ставками, в которых принимаются решения, изменяющие жизнь, также не дает преимущества в точности (например, Caruana et al.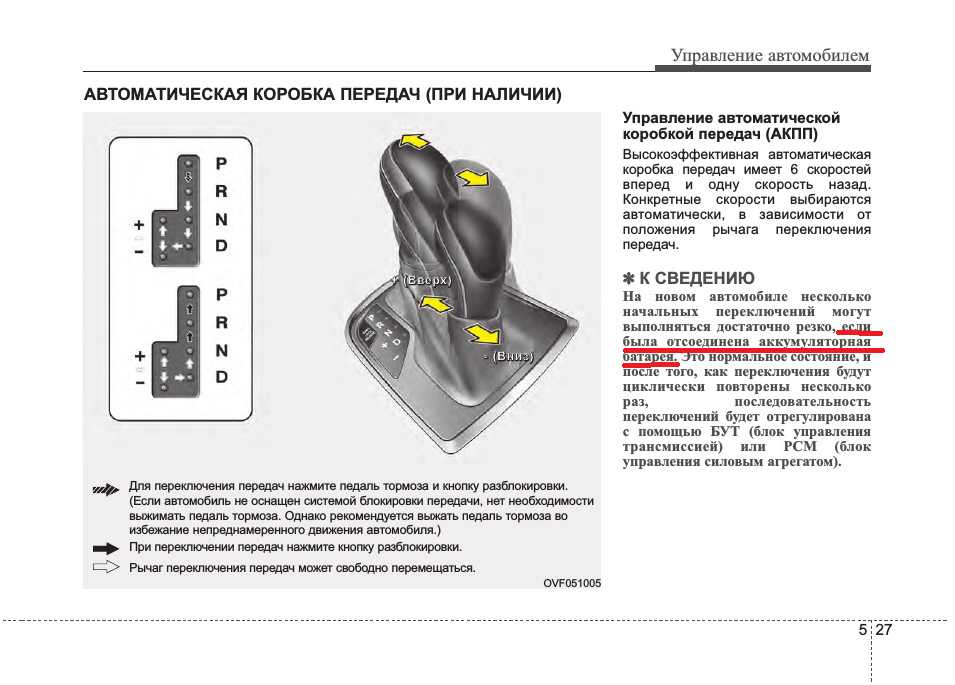 , 2015; Razavian et al., 2015; Rudin & Ustun, 2018, которые демонстрируют модели с ограничениями интерпретируемости, которые работают так же хорошо, как модели без ограничений). Напротив, модели черного ящика могут маскировать множество возможных серьезных ошибок (например, см. Rudin, 2019).). Даже в области компьютерного зрения, где глубокие нейронные сети (наиболее сложный для объяснения вид модели черного ящика) являются самыми современными, мы и другие ученые (например, Chen et al., 2019; Y. Li et al. ., 2017; L. Li, Liu, Chen, & Rudin, 2018; Ming, Xu, Qu, & Ren, 2019) нашли способы добавить ограничения интерпретируемости в модели глубокого обучения, что привело к более прозрачным вычислениям. Эти ограничения интерпретируемости не привели к снижению точности даже для глубоких нейронных сетей для компьютерного зрения.
, 2015; Razavian et al., 2015; Rudin & Ustun, 2018, которые демонстрируют модели с ограничениями интерпретируемости, которые работают так же хорошо, как модели без ограничений). Напротив, модели черного ящика могут маскировать множество возможных серьезных ошибок (например, см. Rudin, 2019).). Даже в области компьютерного зрения, где глубокие нейронные сети (наиболее сложный для объяснения вид модели черного ящика) являются самыми современными, мы и другие ученые (например, Chen et al., 2019; Y. Li et al. ., 2017; L. Li, Liu, Chen, & Rudin, 2018; Ming, Xu, Qu, & Ren, 2019) нашли способы добавить ограничения интерпретируемости в модели глубокого обучения, что привело к более прозрачным вычислениям. Эти ограничения интерпретируемости не привели к снижению точности даже для глубоких нейронных сетей для компьютерного зрения.
Доверие к модели черного ящика означает, что вы доверяете не только уравнениям модели, но и всей базе данных, на основе которой она была построена. Например, в сценарии с роботом и хирургом, не зная, как были оценены 2% и 15%, мы должны усомниться в релевантности этих цифр для какой-либо конкретной группы пациентов.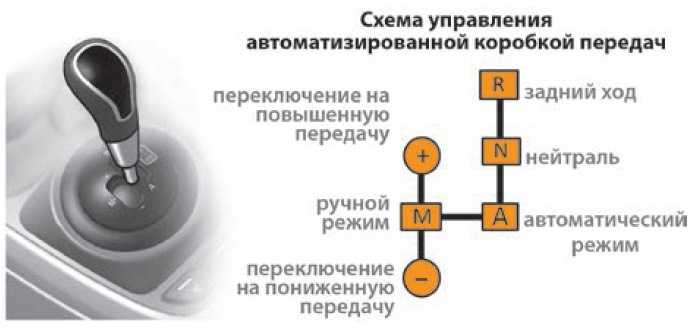 Каждый достаточно сложный набор данных, который мы видели, содержит несовершенства. Они могут варьироваться от огромного количества отсутствующих данных (которые не пропадают случайно) или неучтенных искажений до систематических ошибок в наборе данных (например, неправильное кодирование медикаментозного лечения) до проблем со сбором данных, из-за которых распределение данных отличается от того, что мы изначально думали.
Каждый достаточно сложный набор данных, который мы видели, содержит несовершенства. Они могут варьироваться от огромного количества отсутствующих данных (которые не пропадают случайно) или неучтенных искажений до систематических ошибок в наборе данных (например, неправильное кодирование медикаментозного лечения) до проблем со сбором данных, из-за которых распределение данных отличается от того, что мы изначально думали.
Одной из таких распространенных проблем с моделями черного ящика в медицинских учреждениях является утечка данных, когда некоторая информация о метке y проникает в переменные x таким образом, что вы можете не подозревать, глядя на заголовки и описания переменные: иногда вы думаете, что предсказываете что-то в будущем, но вы только обнаруживаете что-то, что произошло в прошлом. При прогнозировании результатов лечения машина может улавливать информацию из заметок врачей, которая раскрывает результаты лечения пациентов до того, как они будут официально зарегистрированы, и, следовательно, ошибочно заявлять, что это успешные прогнозы.
Пытаясь развеять широко распространенное беспокойство по поводу непрозрачности моделей черного ящика, некоторые ученые пытались предложить их объяснения, гипотезы о том, почему они принимают решения, которые принимают. Такие объяснения обычно пытаются либо имитировать предсказания черного ящика, используя совершенно другую модель (возможно, с другими важными переменными, маскируя то, что на самом деле может делать черный ящик), либо они предоставляют другую статистику, которая дает неполную информацию о расчете черного ящика. . Такие объяснения поверхностны или даже бессодержательны, поскольку они скорее расширяют полномочия черного ящика, чем признают, что в нем нет необходимости. И иногда эти объяснения ошибочны.
Например, когда журналисты ProPublica пытались объяснить, что было в собственной модели COMPAS для прогнозирования рецидивизма (Angwin et al., 2016), они, похоже, ошибочно предположили, что если можно создать линейную модель, которая аппроксимирует COMPAS и зависит от расы, возраста и криминального прошлого, что сам COMPAS должен зависеть от расы. Однако при аппроксимации COMPAS с помощью нелинейной модели явная зависимость от расы исчезает (Rudin, Wang, & Coker, 2019), оставляя зависимость от расы только через возраст и криминальное прошлое. Это пример того, как неправильное объяснение черного ящика может выйти из-под контроля. Возможно, если бы система правосудия использовала только интерпретируемые модели (которые мы и другие продемонстрировали столь же точную), журналисты ProPublica смогли бы написать другую историю. Возможно, например, они могли бы написать о том, что типографские ошибки в этих оценках часто встречаются без очевидного способа их устранения, что приводит к непоследовательному принятию судьбоносных решений в системе правосудия (см., например, Rudin et al., 2019).).
Однако при аппроксимации COMPAS с помощью нелинейной модели явная зависимость от расы исчезает (Rudin, Wang, & Coker, 2019), оставляя зависимость от расы только через возраст и криминальное прошлое. Это пример того, как неправильное объяснение черного ящика может выйти из-под контроля. Возможно, если бы система правосудия использовала только интерпретируемые модели (которые мы и другие продемонстрировали столь же точную), журналисты ProPublica смогли бы написать другую историю. Возможно, например, они могли бы написать о том, что типографские ошибки в этих оценках часто встречаются без очевидного способа их устранения, что приводит к непоследовательному принятию судьбоносных решений в системе правосудия (см., например, Rudin et al., 2019).).
Но еще на конференции NeurIPS 2018 года, в зале, полном экспертов, которые только что предпочли робота хирургу, диктор перешел к описанию конкурса. FICO предоставило набор данных о кредитной линии собственного капитала (HELOC), который содержит данные от тысяч анонимных лиц, включая аспекты их кредитной истории и информацию о том, не выполнил ли этот человек дефолт по кредиту. Цель конкурса состояла в том, чтобы создать модель «черного ящика» для прогнозирования дефолта по кредиту, а затем объяснить «черный ящик».
Цель конкурса состояла в том, чтобы создать модель «черного ящика» для прогнозирования дефолта по кредиту, а затем объяснить «черный ящик».
Можно было бы предположить, что для соревнования, в котором участники должны были создать черный ящик и объяснить его, для задачи действительно нужен черный ящик. Но это не так. Еще в июле 2018 года, когда команда Duke получила данные, поиграв с ними всего неделю или около того, мы поняли, что можем эффективно анализировать данные FICO без черного ящика. Независимо от того, использовали ли мы глубокую нейронную сеть или классические статистические методы для линейных моделей, мы обнаружили, что разница в точности между методами составляет менее 1%, что находится в пределах погрешности, вызванной случайной выборкой данных. Даже когда мы использовали методы машинного обучения, которые давали очень интерпретируемые модели, мы смогли добиться точности, соответствующей лучшей модели черного ящика. В тот момент мы были озадачены тем, что делать. Должны ли мы играть по правилам и предоставить судьям черный ящик и попытаться объяснить это? Или мы должны предоставить прозрачную интерпретируемую модель? Другими словами, что вы делаете, когда обнаруживаете, что вас заставили принять ложную дихотомию между роботом и хирургом?
Должны ли мы играть по правилам и предоставить судьям черный ящик и попытаться объяснить это? Или мы должны предоставить прозрачную интерпретируемую модель? Другими словами, что вы делаете, когда обнаруживаете, что вас заставили принять ложную дихотомию между роботом и хирургом?
Наша команда решила, что для такой важной задачи, как кредитный скоринг, мы не будем предоставлять черный ящик судейской бригаде только для того, чтобы объяснить ее. Вместо этого мы создали интерпретируемую модель, которую, как мы думали, сможет понять даже клиент банка с небольшим математическим образованием. Модель можно было разложить на несколько мини-моделей, каждую из которых можно было понять отдельно. Мы также создали дополнительный интерактивный онлайн-инструмент визуализации для кредиторов и частных лиц. Игра с факторами кредитной истории на нашем веб-сайте позволила бы людям понять, какие факторы были важны для принятия решений по заявке на получение кредита. Чёрного ящика нет вообще. Мы знали, что таким образом, скорее всего, не выиграем соревнование, но нам нужно было сделать более важное замечание.
Можно подумать, что во многих приложениях интерпретируемые модели не могут быть такими же точными, как модели черного ящика. В конце концов, если бы вы могли построить точную интерпретируемую модель, зачем тогда использовать черный ящик? Однако, как показала задача объяснимого машинного обучения, на самом деле существует множество приложений, в которых люди не пытаются построить интерпретируемую модель, потому что они могут полагать, что для сложного набора данных интерпретируемая модель не может быть такой же точной, как модель. черный ящик. Или, возможно, они хотят сохранить модель как собственность. Затем можно было бы предположить, что если можно построить интерпретируемые модели глубокого обучения для компьютерного зрения и анализа временных рядов (например, Chen et al., 2019; Ю. Ли и др., 2017; О. Ли и др., 2018; Ming et al., 2019), то стандарт следует изменить с предположения о том, что интерпретируемые модели действительно , а не существуют, на предположение, что они делают , пока не будет доказано обратное.
Кроме того, когда ученые понимают, что они делают при создании моделей, они могут создавать системы ИИ, которые лучше подходят для людей, которые на них полагаются. В этих случаях так называемый компромисс между точностью и интерпретируемостью оказывается ошибочным: более интерпретируемые модели часто становятся более (а не менее) точными.
Ложная дихотомия между точным черным ящиком и не очень точной прозрачной моделью зашла слишком далеко. Когда сотни ведущих ученых и руководителей финансовых компаний введены в заблуждение этой дихотомией, представьте, как можно одурачить и весь остальной мир. Последствия серьезны: это влияет на функционирование нашей системы уголовного правосудия, наших финансовых систем, наших систем здравоохранения и многих других областей. Давайте настаивать на том, чтобы мы не использовали модели машинного обучения «черный ящик» для принятия решений с высокими ставками, если только нельзя построить интерпретируемую модель, которая достигает такого же уровня точности.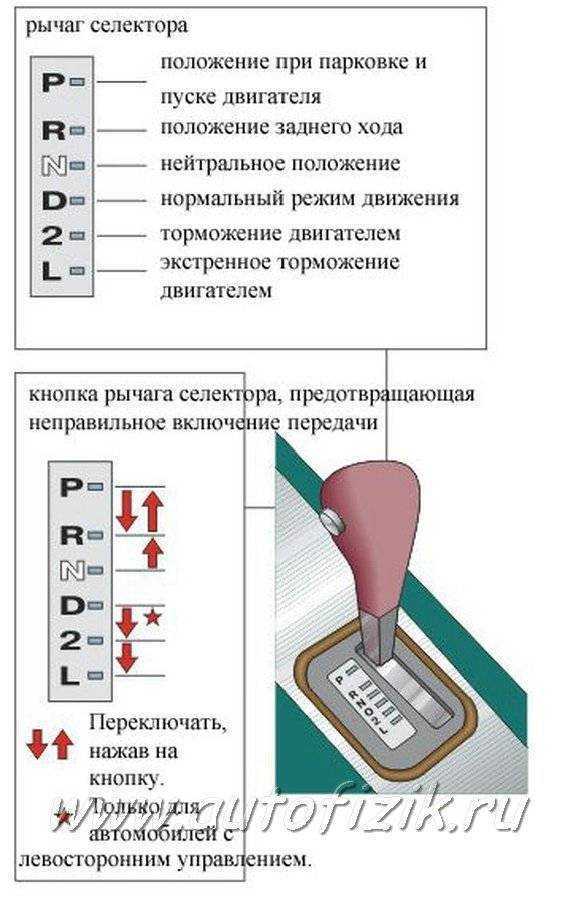 Вполне возможно, что всегда можно построить интерпретируемую модель — мы просто не пытались. Возможно, если бы мы это сделали, мы бы вообще никогда не использовали черные ящики для принятия этих решений с высокими ставками.
Вполне возможно, что всегда можно построить интерпретируемую модель — мы просто не пытались. Возможно, если бы мы это сделали, мы бы вообще никогда не использовали черные ящики для принятия этих решений с высокими ставками.
Веб-сайт конкурса «Объяснимое машинное обучение» находится здесь: https://community.fico.com/s/explainable-machine-learning-challenge
Эта статья основана на опыте Рудина, участвовавшего в конкурсе «Объяснимое машинное обучение» 2018 года. Испытание.
Читатели могут поиграть с нашей интерактивной конкурсной работой здесь: http://dukedatasciencefico.cs.duke.edu
Наша работа действительно не выиграла конкурс, по мнению организаторов конкурса. Судьям вообще не разрешалось взаимодействовать с нашей моделью и инструментом ее визуализации; после истечения крайнего срока подачи было решено, что интерактивные визуализации не будут предоставляться судьям. Тем не менее, FICO провела собственную отдельную оценку конкурсных работ, и наша работа получила хорошие оценки, получив награду FICO Recognition Award за участие в конкурсе.
 Вот объявление FICO о победителях:
Вот объявление FICO о победителях:https://www.fico.com/en/newsroom/fico-announces-winners-of-inaugural-xml-challenge?utm_source=FICO-Community&utm_medium=xml-challenge-page
Что касается авторов знаете, мы были единственной командой, предложившей интерпретируемую модель, а не черный ящик.
 Вот объявление FICO о победителях:
Вот объявление FICO о победителях:Синтия Рудин и Джоанна Радин не раскрывают никакой финансовой или нефинансовой информации для этой статьи.
Анджелино, Э., Ларус-Стоун, Н., Алаби, Д., Зельцер, М., и Рудин, К. (2018). Изучение сертифицированно оптимальных списков правил для категориальных данных. Journal of Machine Learning Research, 18 (1), 8753–8830.
Каруана Р., Лу Ю., Герке Дж., Кох П., Штурм М. и Эльхадад Н. (2015). Понятные модели для здравоохранения: прогнозирование риска пневмонии и 30-дневная повторная госпитализация. В материалах 21-й Международной конференции ACM SIGKDD по обнаружению знаний и интеллектуальному анализу данных (стр.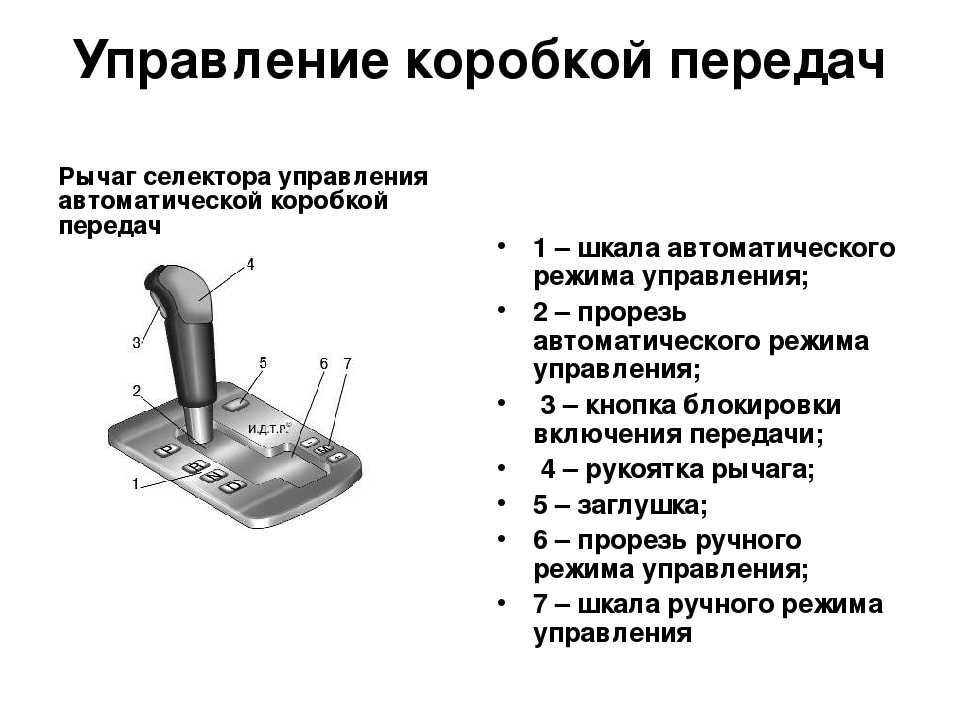 721–1730). https://doi.org/10.1145/2783258.2788613
721–1730). https://doi.org/10.1145/2783258.2788613
Чен, К., Ли, О., Барнетт, А., Су, Дж., и Рудин, К. (2019 г.). Это выглядит так: глубокое обучение для интерпретируемого распознавания изображений. В материалах 33-й Международной конференции по системам обработки нейронной информации (статья 801).
Ли, О., Лю, Х., Чен, К., и Рудин, К. (2018). Глубокое обучение для рассуждений на основе прецедентов с помощью прототипов: нейронная сеть, которая объясняет свои прогнозы. In Материалы тридцать второй конференции AAAI по искусственному интеллекту и тридцатой конференции по инновационным приложениям искусственного интеллекта и восьмого симпозиума AAAI по достижениям в области образования в области искусственного интеллекта (статья 432).
Ли Ю., Муриас М., Мейджор С., Доусон Г., Дзираса К., Карин Л. и Карлсон Д. Э. (2017). Нацеливание на синхронность ЭЭГ/ЛФП с помощью нейронных сетей. В материалах 31-й Международной конференции по системам обработки нейронной информации (стр. 4620–4630).
4620–4630).
Мин, Ю., Сюй, П., Цюй, Х., и Рен, Л. (2019). Интерпретируемое и управляемое обучение последовательности с помощью прототипов. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining (стр. 903–913). https://doi.org/10.1145/3292500.3330908
Разавиан, Н., Блекер, С., Шмидт, А. М., Смит-Маклаллен, А., Нигам, С., и Зонтаг, Д. (2015). Прогнозирование диабета 2 типа на уровне населения на основе данных о претензиях и анализа факторов риска. Большие данные, 3 (4) , 277–287. https://doi.org/10.1089/big.2015.0020
Ангвин, Дж., Ларсон, Дж., Матту, С., и Киршнер, Л. (2016, 23 мая). Машина смещения . ПроПублика. https://www.propublica.org/article/machine-bias-risk-assessments-in-criminal-sentencing
Рудин К. (2019). Прекратите объяснять модели машинного обучения «черный ящик» для принятия решений с высокими ставками и вместо этого используйте интерпретируемые модели.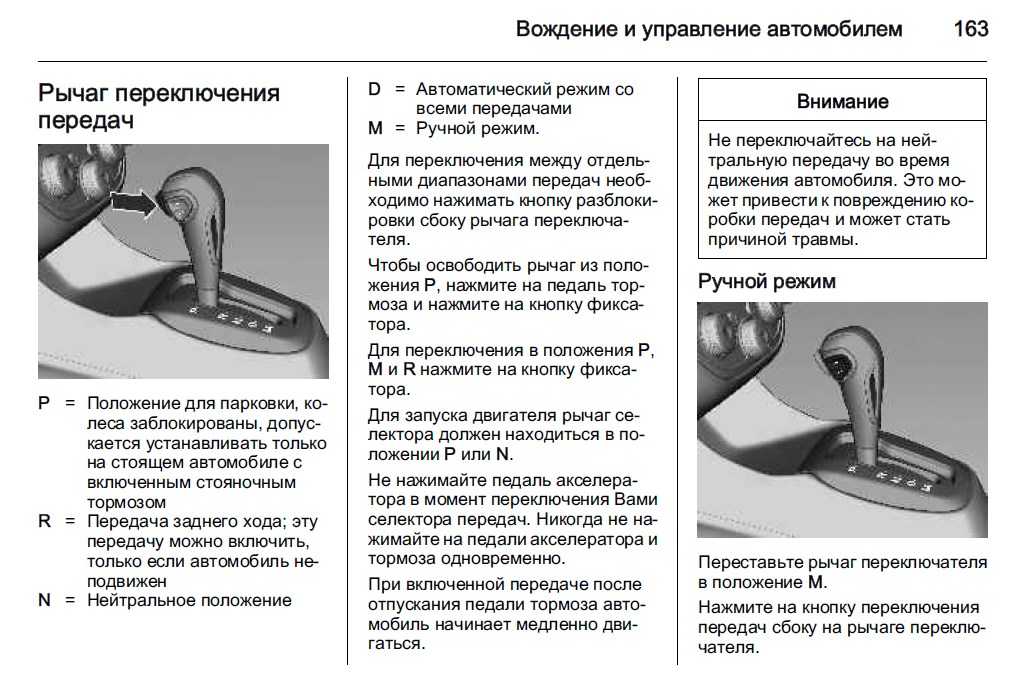 Природный машинный интеллект, 1 , 206–215. https://doi.org/10.1038/s42256-019-0048-x
Природный машинный интеллект, 1 , 206–215. https://doi.org/10.1038/s42256-019-0048-x
Рудин, К., и Устун, Б. (2018). Оптимизированные системы оценки: на пути к доверию к машинному обучению в здравоохранении и уголовном правосудии. Интерфейсы, 48 (5) , 449–466. https://doi.org/10.1287/inte.2018.0957
Рудин, К., Ван, К., и Кокер, Б. (2019 г.). век секретности и несправедливости в предсказании рецидивизма. Harvard Data Science Review, 2 (1). https://doi.org/10.1162/99608f92.6ed64b30
Толленаар, Н., и ван дер Хейден, П. Г. М. (2013). Какой метод лучше всего предсказывает рецидив? Сравнение моделей прогнозирования статистики, машинного обучения и интеллектуального анализа данных. Журнал Королевского статистического общества, серия A: Статистика в обществе, 176 (2), 565–584. https://doi.org/10.1111/j.1467-985X.2012.01056.x
Цзэн, Дж., Устун, Б., и Рудин, К. (2016). Интерпретируемые модели классификации для прогнозирования рецидивизма.